Chapter 1: Set Theory
Mathematics is fundamentally about studying patterns, structures, quantities, and logical reasoning. In this context, set theory is a part of the foundational language of mathematics, providing an important framework for clearly describing and discussing collections of objects. Understanding sets and their notation is crucial as they form the basis for more complex mathematical structures and reasoning.
Set Basics
Definition of a Set
A set is a well-defined collection of distinct objects, called elements.
- Notation: Sets are typically written using curly braces and denoted by capital letters from the Latin alphabet, such as .
- Well-defined: The objects inside a set, i.e., its elements, must be well-defined, meaning it is always clear whether something belongs to the set or not.
- Distinct Elements: A set contains only distinct elements; no duplicates are allowed.
- Order Independence: The order of elements in a set does not matter. For example, and represent the same set.
The elements , , and are placeholders and can represent anything — numbers, symbols, objects, or even abstract concepts — as long as they are clearly identifiable.
To better solidify the concept of a set, we now present a few illustrative examples.
Consider the set of vowels in the English alphabet:
This set clearly lists all the vowels, and it is easy to determine whether a given letter is a vowel or not.
For a set to be meaningful, it must be well-defined. This means it must be clear whether any given object is an element of the set or not. For example, the set of vowels in the word "radio" is well-defined and can be written as:
Similarly, the "set of all days last year with temperatures below C" is well-defined because it is based on objective, measurable data. However, the "set of all cold days last year" is not well-defined because the term "cold" is subjective and can vary from person to person.
The set of vowels in the English alphabet is:
Note that the following is not a valid set because it contains duplicate entries:
In sets, each element must be distinct, so duplicates are not allowed.
Consider two sets containing the vowels in the English alphabet:
These two sets are identical because they contain the same elements, regardless of the order in which the elements are listed. Thus, we can write:
This example illustrates the concept of order independence in sets, where the arrangement of elements does not define the uniqueness of a set.
The empty set is the unique set that contains no elements. It is denoted by or simply .
Even though it has no elements, it plays a key role in set theory, similar to how plays a key role in arithmetic.
Representing Sets
Sets can be described using various notations, each suited to different contexts. Choosing the appropriate notation depends on the nature of the set (finite vs. infinite, discrete vs. continuous) and the intended level of clarity of communication. Below, we discuss the most common methods of representing sets, along with their advantages and typical use cases.
Verbal Description
A verbal description uses ordinary language to define a set by explaining its elements or properties. This approach is particularly useful for introducing abstract or unfamiliar sets in an intuitive way or for providing context before formalizing the set with mathematical notation.
- "The set of vowels in the English alphabet."
- "The set of whole numbers."
- "The set of whole numbers strictly smaller than 6."
Roster Form
Roster form explicitly lists all elements of a set enclosed in curly braces . This notation is particularly useful for finite sets or infinite sets with clear, recognizable patterns.
-
The set of vowels in the English alphabet:
-
The set of whole numbers:
-
The set of whole numbers strictly smaller than 6:
Note: The ellipsis () indicates that the pattern continues indefinitely.
Set-Builder Notation
Set-builder notation provides a precise and compact way to define a set by specifying the properties that its elements must satisfy. The notation takes one of two equivalent forms:
Both forms are read as "the set of all such that the given condition holds".
Here, the symbol represents a generic element of the set, i.e., it does not refer to any particular element but serves as a placeholder for all possible elements that satisfy the condition. The vertical bar () or colon () functions as a divider between the variable and the rule that determines which elements belong to the set.
For example, the condition might express a numerical restriction such as (meaning is strictly greater than zero), a combined relationship like (meaning lies strictly between zero and ten), or a membership rule such as (meaning is an element of the set ). In each case, the notation highlights the defining property rather than listing individual elements.
Because of this, set-builder notation is preferred when working with infinite sets, continuous intervals, or sets defined by more complex conditions.
-
The set of vowels in the English alphabet:
-
The set of whole numbers:
-
The set of whole numbers strictly smaller than 6:
Interval Notation
Certain sets appear so frequently in mathematics that they are assigned dedicated symbols. One of the most fundamental is the set of real numbers, denoted by . This set, also often just called the "reals", includes virtually any number we can think of, such as , , , , , , and .
Geometrically, can be visualized as an infinite line, where each point corresponds to a real number. Intervals are contiguous segments of this line, representing subsets of .

To describe intervals concisely, we use interval notation, which employs brackets to indicate inclusive bounds and/or parentheses to indicate exclusive bounds.
Below is a summary of how interval notation corresponds to sets of real numbers together with their corresponding set-builder notation.
| Set | Interval Notation | Set-Builder Notation | Illustration |
|---|---|---|---|
| All real numbers | |||
| Open interval | |||
| Closed interval | |||
| Infinite to the right | |||
| Infinite to the right | |||
| Infinite to the left | |||
| Infinite to the left | |||
| Half-open (left open) | |||
| Half-open (right open) |
Understanding how elements relate to sets is fundamental — not only when defining a single set, but also when comparing and working with multiple sets. In the next section, we explore these relationships in more detail and introduce their formal notation.
-
Real numbers strictly between and :
-
Real numbers between and , including both endpoints:
-
Real numbers greater than :
-
Real numbers less than or equal to :
Set Membership
Set membership describes the fundamental relationship between elements and a set. This relationship is crucial for defining and understanding the contents of sets.
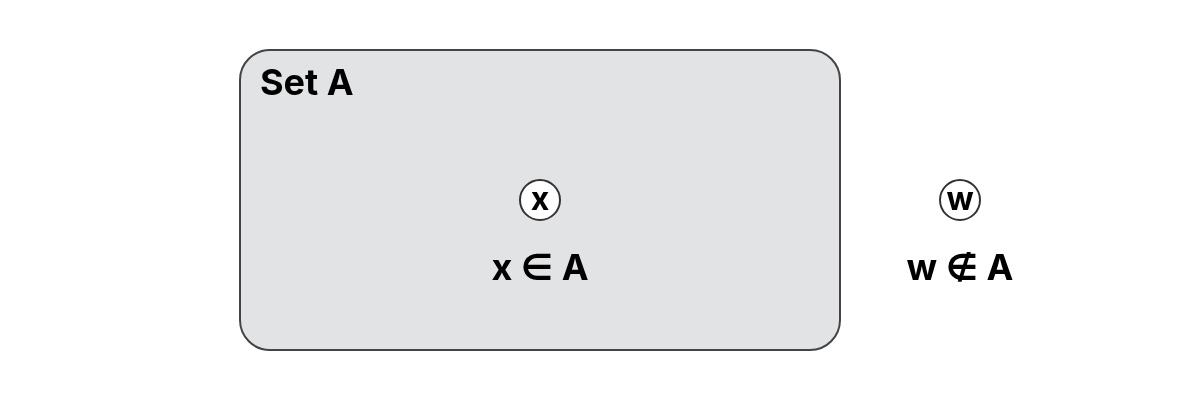
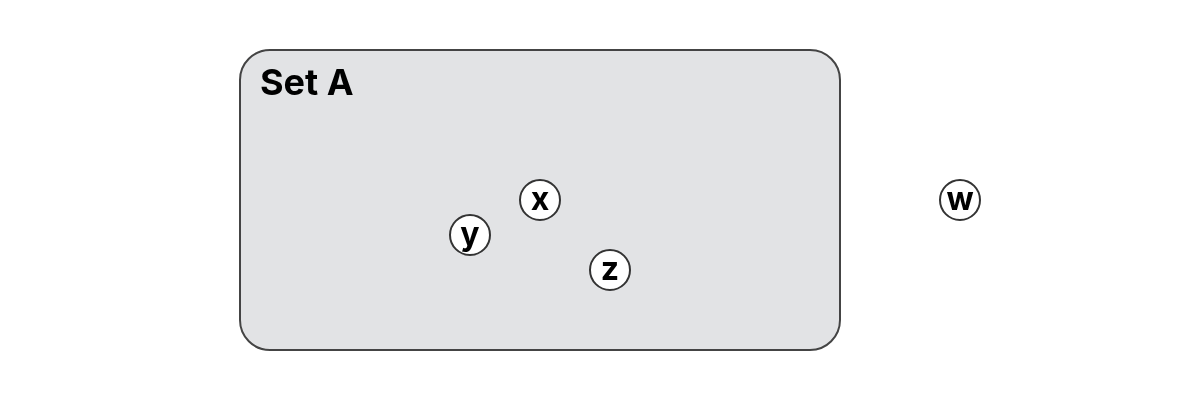
Let be an element and a set. We say that is an element (or member) of , written , if and only if belongs to the collection of elements that make up . If an element is not in , we write .
The following examples illustrate how we use the symbols (is an element of) and (is not an element of) to describe whether a value belongs to a particular set.
-
The element belongs to the set because it appears among its members:
-
The element does not belong to the set because it is not included among its elements:
-
The number is a real number, so it belongs to the set of all real numbers:
-
In this case, the elements of the outer set are themselves sets, so is one of its members:
-
The number alone is not a member, because the set only contains sets as elements:
-
The fraction (equal to ) is in the interval because :
-
The number is not in this interval because it is not positive:
This binary relationship, where each element either belongs to a set or does not, precisely defines a set’s contents and forms the basis for defining equality and more advanced set relations.
Two sets and are equal, denoted , if they contain exactly the same elements. This means every element of is in , and every element of is in . More formally, in predicate logic, we can write this as:
Or in plain words: Two sets and are equal if and only if every element belongs to exactly when it belongs to .
Cardinality
The cardinality of a set , written , indicates the number of elements in . In other words, the cardinality is the size of .
- If , then . This means that is a finite set and has five distinct elements.
- If , then . This means that is a finite set and has six distinct elements.
- If , then (aleph-null, the cardinality of any countably infinite set). This means that is countably infinite, i.e., its elements can be listed one by one in an endless sequence (first 1, then 2, then 3, and so on).
- If , then (the cardinality of the continuum). The set of real numbers is uncountably infinite, it is so large that it is impossible to list all elements in any sequence; between any two real numbers, there are infinitely many others.
- If , then . The empty set contains no elements, so its cardinality is zero.
Equivalence of Sets
Two sets and are said to be equivalent, often written , if they have the same number of elements.
Formally, and are equivalent if there exists a one-to-one correspondence (a bijection) between their elements, i.e., each element of can be paired with exactly one element of , and every element of is matched with exactly one element of .
In terms of size, this means their cardinalities are equal:
Consider the two sets of numbers:
These sets are equal () because they contain exactly the same elements.
Now consider:
These sets are not equal, since their contents differ, but they are equivalent () because each element of can be matched with one element of .
In most cases, we care about equality when we want to check whether two things are exactly the same. But sometimes we only care whether two things share a certain property, for example, having the same size, and that is where equivalence becomes useful.
The same idea appears in many areas of mathematics. Some simple examples are:
-
Two fractions such as and are equivalent because they represent the same value. Evaluating both gives , but the fractions themselves are written differently.
-
Two equations like and are equivalent because they have the same solution. The value satisfies both equations, even though their forms differ.
-
Two angles are equivalent if they have the same measure, even if they open in different directions.
- In geometry, shapes that are the same in size and form, though placed differently, are also considered equivalent through congruence.

Subsets & Proper Subsets
Subsets and proper subsets describe the relationship between sets in terms of their elements.
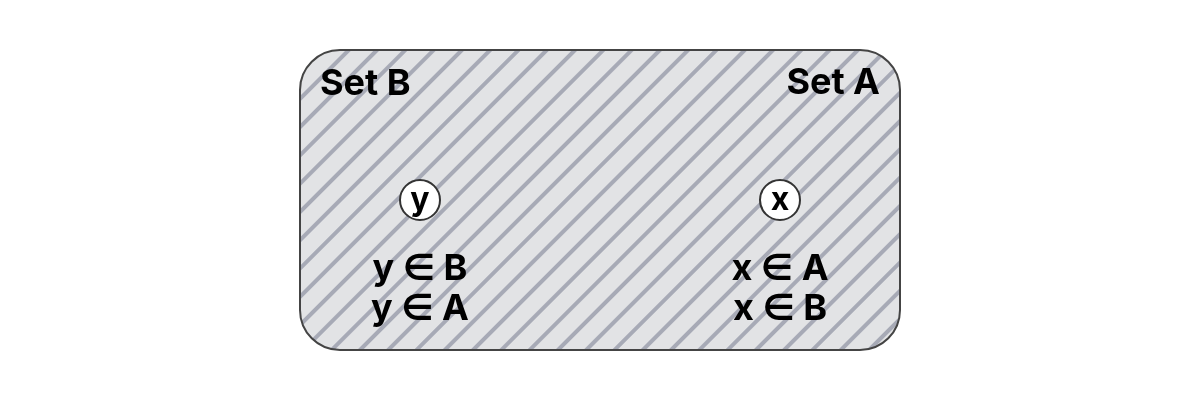
Let and be sets. We say that is a subset of if and only if every element of is an element of . We write to denote the fact that is a subset of .
-
Let and . Since both sets contain the same elements, we have that: Therefore, and are equal sets, and each is a subset of the other.
-
Let and . The empty set contains no elements, so it is a subset of every set:
-
Let and . Every element of is in , so: Since has more elements, is also a proper subset, but we can first identify it as a subset.
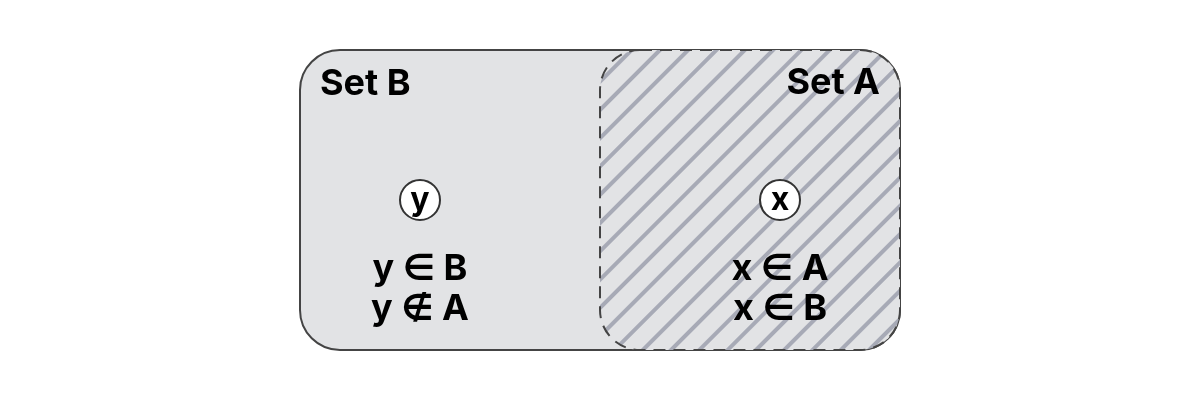
If is a subset of , but is not equal to (, meaning contains fewer elements than ), then is called a proper subset of , which we denote by .
If a subset contains all the elements of the original set, it is still considered a subset, but not a proper one.
-
Let and . Every element of is in , but has one additional element. Therefore: That is, is a proper subset of .
-
Similarly, if we let and , Then all elements of are contained in , but has additional elements ( and ). Hence: That is, again, is a proper subset of .
These examples show that a proper subset is always strictly smaller, that is, a proper subset includes some, but not all, of the elements of the larger set.
The Universe and Set Complement
The universe and set complement relate to what is not contained in a given set. Before exploring complements, we must first understand the universe that defines the context for all sets.
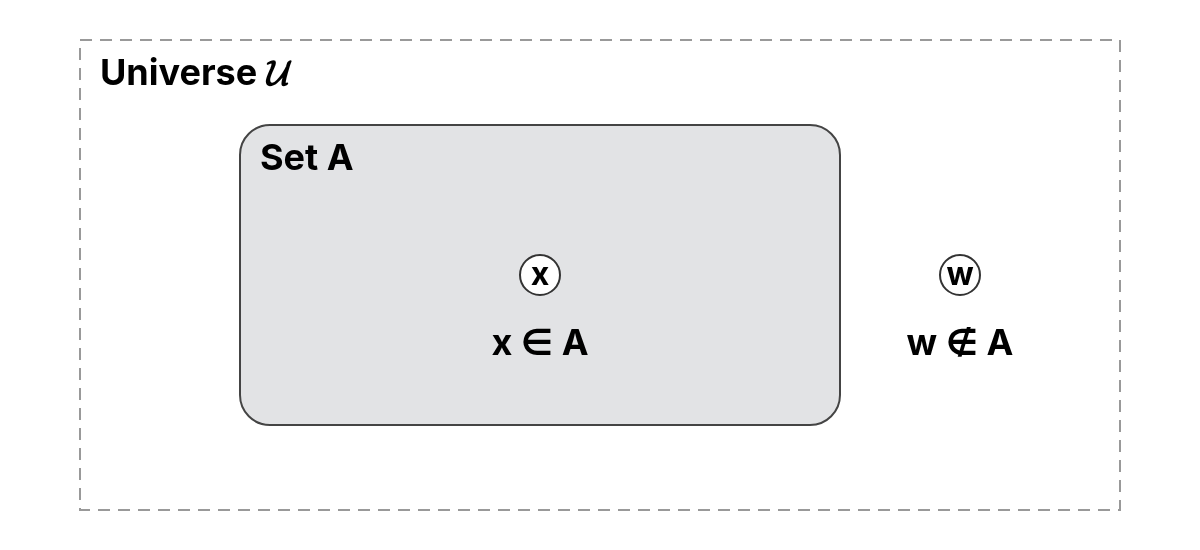
The universe, often denoted as , refers to a set that contains all the objects or elements relevant to a particular discussion or problem. It serves as the context within which all other sets are defined and interpreted.
-
Let the universe be the set of all lowercase English letters: Then we can define:
- , the set of vowels.
- , the set of consonants.
Here, provides a clear context: and together cover all letters in the alphabet.
-
Let the universe be the set of all real numbers: Then we can define:
- . The set of all real numbers strictly between and .
- . The set of all real numbers between 2 and 5, including the endpoints.
- . The set of all real numbers greater than 3.
In this case, defines the entire number line, and each of these sets represents a subset of it.
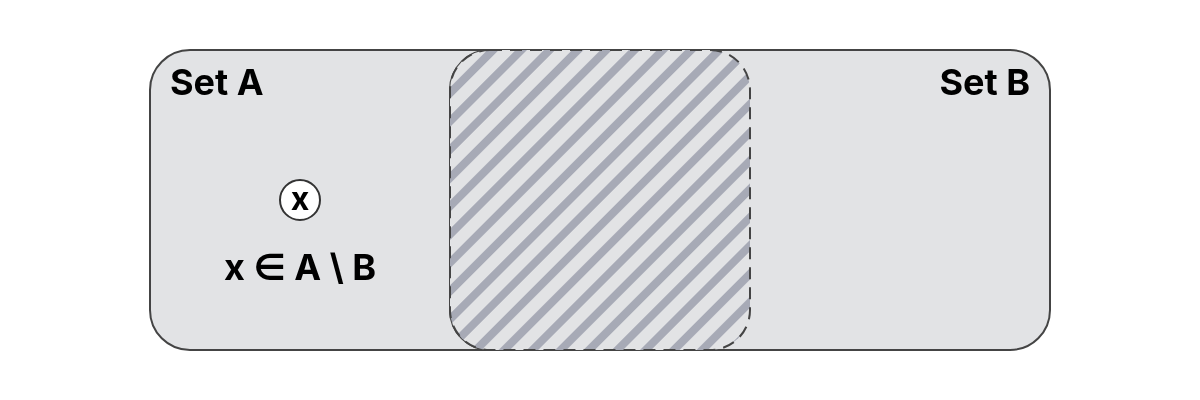
The set difference of two sets and , denoted as , is the set of all elements that are in but not in .
In other words, it removes from all elements that also belong to .
-
Let and . Then: These are the vowels that are not in the set .
-
Let and . The elements in that are not in are:
-
Let and . The fruits in that are not in are:
-
Let and . Since and contain the same elements, we have that: That is, the difference is the empty set because there is nothing in that is not in .
-
Let and . Then: The difference consists of the endpoints of the closed interval that are not part of the open interval .
These examples show that the set difference identifies what belongs only to the first set and not to the second.
Now that we understand how to subtract one set from another using set difference, we can define the complement of a set as a special case, subtracting from the universe.
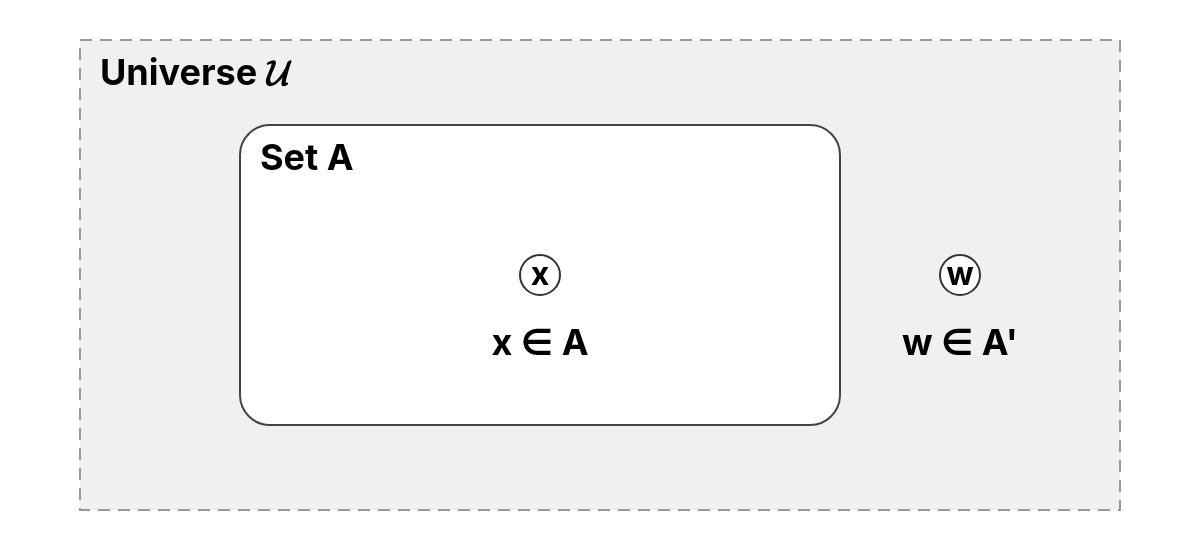
The complement of a set , denoted as , consists of all elements in the universe that are not in . In other words:
The complement provides a way to discuss what is not included in a set within the context of a given universe.
-
Let and . The complement of is: Here, contains the elements of that are not in .
-
Let be the set of vowels in the English alphabet. If the universe is the set of all lowercase letters, then the complement is: Here, the complement is expressed verbally to save space, but we could list all consonants explicitly if desired.
-
Let be a standard deck of playing cards, and let be the set of all spades. The complement is: In this context, represents every card that is not a spade.
-
Let and . The complement of is: This means contains all real numbers less than or equal to 10.
These examples illustrate how the complement operation identifies everything outside a given set, relative to a specified universe .
Special Number Sets
As mentioned earlier, certain sets of numbers frequently appear and are often represented by special symbols. These sets range from the most basic counting numbers to the broadest set of real numbers.
Below is a summary of some of the fundamental number sets you will encounter, along with their common notations, definitions, and examples.
Fundamental Number Sets
| Symbol | Name | Definition / Description |
|---|---|---|
| Natural numbers | The counting numbers. | |
| Natural numbers with zero | The natural numbers including . | |
| Integers | All whole numbers, both positive and negative. | |
| Rational numbers | The numbers that can be written as fractions. | |
| Irrational numbers | The real numbers that cannot be written as fractions (e.g., , , ). | |
| Real numbers | All numbers on the continuous number line. Includes both and . | |
| Complex numbers | Numbers with a real part and an imaginary part . Includes all real numbers as a subset. |
These number sets are not isolated; rather, they form a natural hierarchy where smaller sets are contained within larger ones. The diagram below shows how these sets nest inside one another, for example, all natural numbers are integers, all integers are rational numbers, and all rational numbers are real numbers.
Although irrational numbers are not shown explicitly, they form the part of the real numbers that lies outside the rationals.

The hierarchy can also be expressed symbolically as:
Understanding this hierarchy helps clarify how different number systems extend one another, expanding the kinds of quantities we can represent and reason about.
Additional Set Operations
A few other foundational set operations are commonly used in mathematics and thus data science. While we will not cover these in detail in this course, the table below provides a brief overview. You will most likely encounter and work with these operations throughout your data science degree.
| Symbol | Operation | Description |
|---|---|---|
| Intersection of and | The set of all elements that are in both and | |
| Union of and | The set of all elements that are in , in , or in both | |
| Cartesian product of and | The set of all ordered pairs where and | |
| The power set | The set of all subsets of , including the empty set () and itself |
Chapter Exercises
Write the following sets in roster form (if possible). If it is not possible, explain why.
- The set of first five positive and even whole numbers.
- The real numbers in the interval
- The set of whole numbers less than 6.
- The set of whole numbers that are considered very small.
- The set of letters in the word "banana".
- The set of even numbers that are typically interesting.
- The real numbers in the interval
Use set-builder notation to describe the following sets:
- , , and
Use interval notion to describe the following sets:
- The set of all real numbers between 2 and 5, including both endpoints.
- The set of all real numbers strictly greater than .
- The set of all real numbers less than or equal to .
- The set of all real numbers greater than and less than or equal to .
- The empty set (in terms of intervals).
For each pair of sets below, determine whether they are (a) equal, (b) equivalent but not equal, (c) neither equal nor equivalent.
- Let and
- Let and
- Let and
- Let and
- Let and
Let , , and . State whether each is true, false, or meaningless:
List all elements of the following sets:
Let , , and . Find each of the following sets:
Chapter 2: Algebra
This chapter revisits some fundamental algebraic rules involving fractions, exponents, polynomials, and the use of parentheses. A firm grasp of these ideas is essential, since many common mistakes in computation and symbolic manipulation arise from misunderstanding or misapplying these basic principles.
Algebraic expressions and their underlying rules appear across a wide range of mathematical contexts. Developing the ability to recognize, interpret, and manipulate such expressions is therefore a key skill—both for simplifying symbolic formulas and for solving more complex problems in later chapters.
Unless otherwise specified, all constants, variables, and placeholders are assumed to belong to subsets of the real numbers (i.e., ).
In other words, when we perform standard operations such as addition, subtraction, multiplication, or division (except division by zero), the results remain within .
Basic Algebraic Properties
Before we explore more advanced algebraic concepts, it is useful to recall a few basic properties that govern addition and multiplication. These properties, i.e., the commutative, associative, and distributive laws, apply to all real numbers and allow us to manipulate expressions, regardless of how they are written or grouped.
The commutative law states that the order of two elements does not affect the result:
The associative law states that the way elements are grouped does not affect the result:
The distributive law of multiplication over addition (and subtraction):
This property allows us to distribute a factor across terms inside parentheses.
Consider the expression:
Using the distributive law, we multiply by each term inside the parentheses:
The result is the same as first adding the terms inside the parentheses and then multiplying:
This confirms that the distributive and associative properties are consistent, i.e., the order in which we group or distribute the factors does not change the result.
Consider the expression:
Here, the negative sign in front of the parentheses can be interpreted as multiplying by :
Applying the distributive law, we multiply by each term inside the parentheses:
This shows that placing a negative sign in front of parentheses changes the sign of each term inside.
Fractions
Fractions represent parts of a whole and are especially useful when dealing with proportions, ratios, and percentages. A fraction consists of two parts:
- A numerator (top number): represents how many parts we have.
- A denominator (bottom number): represents how many equal parts make up the whole.
In symbolic form, a fraction is written as a ratio of two integers:
The set of all such numbers is called the rational numbers and denoted by , and it forms a subset of the real numbers:
Adding fractions is not done by simply adding the numerators and denominators:
For example:
but
which is incorrect for addition. Always use a common denominator as explained below.
To add or subtract fractions, the denominators must be the same. Once a common denominator is found, we can add (or subtract) the numerators and keep the denominator unchanged.
If the denominators are already the same:
If they are different, multiply each numerator by the other fraction’s denominator to obtain a common base:
-
Evaluate the following expression (fractions with the same denominator):
-
Evaluate the following expression (fractions with different denominators):
-
Evaluate the following expression (subtracting two fractions):
Multiplication of fractions is straightforward: multiply the numerators together and the denominators together.
-
Evaluate the following expression (multiply two fractions directly): Multiplying straight across gives , which simplifies to .
-
Evaluate the following expression (simplify before multiplying): Since appears in both numerator and denominator, it can be simplified before or after multiplication.
-
Evaluate the following expression (multiply a whole number by a fraction): Whole numbers can be treated as fractions with denominator , making the same rule apply.
To divide one fraction by another, multiply the first fraction by the reciprocal (or multiplicative inverse) of the second fraction.
-
Evaluate the following expression (divide one fraction by another): The reciprocal of is ; multiplying gives .
-
Evaluate the following expression (divide by a smaller fraction): Dividing by a smaller fraction increases the result, since fits multiple times into .
-
Evaluate the following expression (divide a fraction by a whole number): Note here that the whole number can be written as , and its reciprocal is .
The rational numbers are closed under addition, subtraction, multiplication, and division (except division by zero). This means performing these operations on fractions always produces another rational number.
Exponents
Exponents indicate how many times a base number is multiplied by itself. For example:
In these expressions, the base ( and , respectively) tells us what to multiply, while the exponent ( and , respectively) tells us how many times to multiply it.
Exponents essentially provide a compact way to represent repeated multiplication and follow a consistent set of algebraic rules, which we go into details with below.
For any nonzero base , raising it to the power of zero equals 1:
The reason must be nonzero is to avoid ambiguity. Depending on how we reason about it, we can arrive at two conflicting interpretations. From one perspective, since for any positive , it might seem natural to conclude that . From another, because for any positive , one could instead argue that . These two lines of reasoning contradict each other, so is left undefined to avoid inconsistency.
When multiplying powers that share the same (nonzero) base (), we add their exponents ( and ):
This rule follows from the idea that each exponent represents repeated multiplication of the same base, and combining them extends that repetition into just a single product.
In the following we apply the Product of Powers rule to see how it works. That is, we evaluate the following expression:
Here, each exponent counts how many times the base 2 appears as a factor. Combining both terms gives factors of 2 in total.
When raising an exponential term () to another power (), we simply multiply the exponents:
This rule reflects that each copy of contributes factors of , and there are such copies in total, giving us factors altogether.
In the following we apply the Power of a Power rule to see how it works. That is, we evaluate the following expression:
Here, the inner exponent () tells us there are three factors of 5 in each group, and the outer exponent () tells us there are two such groups. Altogether, we get factors of 5.
When a base () is raised to a negative exponent (), the result is the reciprocal of the base () raised to the corresponding positive exponent ():
This rule essentially expresses that a negative exponent "flips" the base, moving it from the numerator to the denominator.
Let us apply the Negative Exponent rule to see how it works.
- First let us evaluate an expresseion when the base is positive:
- Next, we evaluate an expression when the base is negative:
When dividing powers that share the same base (), then we subtract the exponents ( and ).
This rule follows directly from the Product of Powers and Negative Exponent rules, i.e., division is simply multiplication by the reciprocal:
This rules apply when , since division by zero is undefined.
Let us apply the Quotient of Powers rule to see how it works directly:
We can also expand the numerator and denominator to illustrate how factors cancel out:
Here, the two factors of 3 in the denominator remove two factors from the numerator, leaving factors in total.
Roots can be expressed as fractional exponents. In general, the -th root of can be written as follows:
This allows us to apply exponent rules even when working with roots, as roots are simply another form of exponentiation.
Let us apply the rule by expressing roots as fractional exponents:
-
The square root of a number:
-
The cube root of a number:
-
The fourth root of a power:
Here, the denominator of the exponent corresponds to the root, while the numerator corresponds to the power.
The root of a product is equal to the product of the roots (for non-negative and ):
For square roots (), this simplifies to:
This property holds only for non-negative real numbers, since roots of negative numbers are not real (they care complex numbers).
Let us apply the Product of Roots rule to simplify a root expression:
Here, expressing as allows us to separate the square root into two simpler factors,
making the simplification straightforward.
All these exponent rules apply for any real exponent, not just integers.
However, it is generally not possible to simplify expressions such as when the bases are different and unrelated by a common factor.
Likewise, exponent rules do not apply to addition or subtraction, so expressions like cannot be simplified using these rules.
Algebraic Identities
When working with algebraic expressions, we often encounter recurring patterns that make calculations simpler. The commutative, associative, and distributive laws, together with the rules of exponents, provide the foundation for manipulating and simplifying such expressions.
In particular, by applying the distributive law repeatedly, and interpreting exponents like or as repeated multiplication, we can derive a number of useful algebraic identities. These identities, summarized in the table below, describe common patterns that occur when expanding or factoring expressions and offer compact formulas that are helpful in later algebraic work.
| Name | Expression | Factored Form | Expanded Form |
|---|---|---|---|
| Square of a Sum | |||
| Square of a Difference | |||
| Difference of Squares |
Chapter Exercises
Chapter 3: Functions
Definition & Notation
A function is a relation between two sets, where each element of the first set (called the domain) is assigned to exactly one element of the second set (called the codomain). As illustrated below, a function can be thought of as an input/output device : for any given input, the output is uniquely determined.
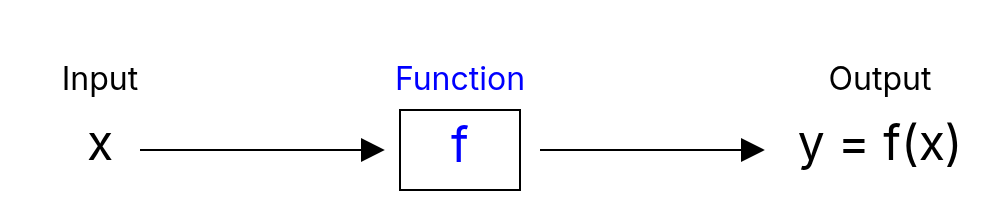
We now provide a more formal definition of a function and introduce several related concepts.
A function is a rule that assigns to each input exactly one output . This relationship is often written as:
In particular:
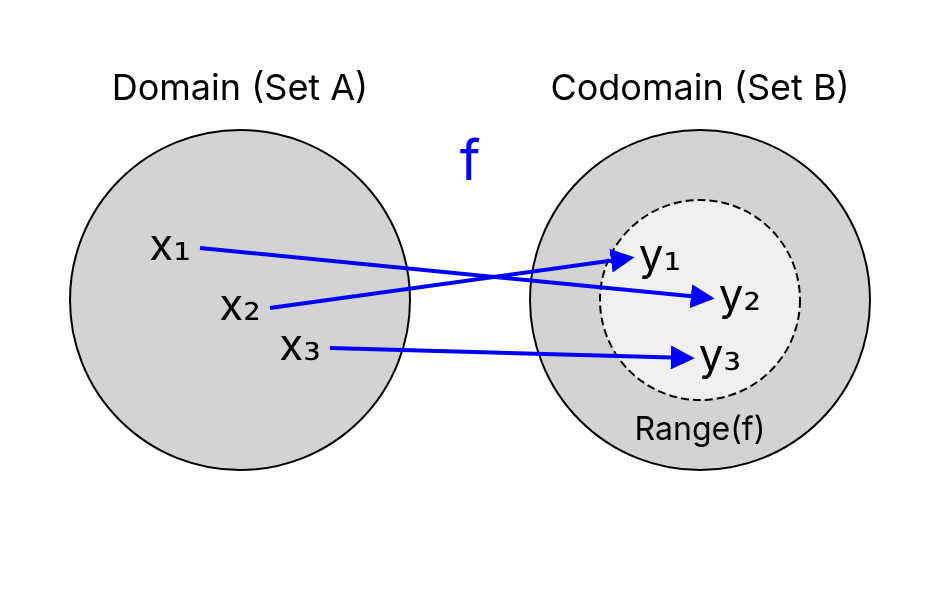
- The set is called the domain of the function. It contains all possible valid inputs.
- The set is called the codomain. It is the set into which all outputs are mapped.
- The range (also called the image) of the function is the set of actual outputs the function produces based on its domain. It is a subset of the codomain:
When we use to denote the input and to denote the output associated with , is also referred to as the independent variable and as the dependent variable, because its value "depends on ".
A function always has a domain, which is the set of all inputs for which the function is defined. If no specific domain is stated for a function given by an equation, the default is typically the set of all real numbers that yield valid (usually real) outputs.
Functions are powerful tools for describing relationships between two quantities. Many real-world scenarios can be modeled using functions, where one variable depends on another. In this context, it is also important to understand a function’s domain, codomain, and range, as these concepts help clarify what kinds of inputs are valid, what types of outputs are expected, and what outputs actually occur.
The area of a square depends on the length of its side. If the side length is , the area is given by
- Domain: , because side lengths cannot be negative.
- Codomain: , since the function produces real-number outputs (areas measured in real units).
- Range: , because squaring any non-negative number gives a non-negative result. The smallest value occurs at , where , and as increases, grows without bound.
The temperature at a given time of day can be expressed as a function of time. Suppose the temperature (in °C) follows the rule
- Domain: , because the model describes temperature over a single day (in hours).
- Codomain: , since temperature values are real numbers.
- Range: , since the sine term varies between and . This means varies between and , and adding shifts the range to .
If a car travels at a constant speed of 60 km/h, the distance traveled after hours is given by
- Domain: , because time cannot be negative.
- Codomain: , since distances are expressed as real numbers.
- Range: , because multiplying a non-negative by 60 produces a non-negative result. The distance is at the start, and increases without bound as time increases.
The codomain defines the set of values a function is declared to produce, while the range consists of the values that actually occur.
In many cases, the codomain is chosen to be the set of real numbers, , even when the outputs are only non-negative (as in Example 1). This convention keeps real-valued functions compatible with one another, i.e., it allows us to compare, combine, and apply the same rules (for example, addition, composition, or differentiation) without worrying about mismatched output sets.
In general, the codomain specifies the structure of the output space: it tells us what kind of values a function is expected to produce, while the range shows which of those values actually occur.
Representation Methods
Functions can be represented in several different ways, each offering different insights into the relationship they describe. Depending on the context, one representation may be more useful or informative than another.
To illustrate these representations, we will use a simplified example based on (synthetically generated) agriculture data. Let denote the crop yield (in t/ha) as a function of fertilizer amount (in kg/ha). That is, we define:
This example models a common real-world scenario where one quantity (fertilizer) depends on another (crop yield).
Tables
A table is one of the most straightforward ways to represent a function. This form is especially useful when working with data collected through observation or measurement. Essentially, a table just lists specific input values and their corresponding output values.
| Fertilizer () | Crop Yield () |
|---|---|
| 0 | 3.4942 |
| 1 | 3.5038 |
| 2 | 3.5133 |
| 3 | 3.5228 |
| 4 | 3.5322 |
| 197 | 4.1589 |
| 198 | 4.1559 |
| 199 | 4.1530 |
| 200 | 4.1500 |
| 201 | 4.1469 |
| 396 | 2.3319 |
| 397 | 2.3163 |
| 398 | 2.3008 |
| 399 | 2.2851 |
| 400 | 2.2694 |
In this table, each row shows a specific input value and the corresponding output value . Tables are useful for answering discrete queries, such as: "What is the crop yield if given 200 kg/ha fertilizer?".
They can also help identify general trends in the data, which leads us to the following definitions.
We say that a function is increasing on an interval if for all it holds that
The function is said to be strictly increasing (note the inequality) when
We say that a function is decreasing on an interval if for all it holds that
The function is said to be strictly decreasing (note the inequality) when
By applying these definitions and inspecting the table, we can observe that the crop yield increases as the fertilizer amount increases - up to a certain point - and then decreases. However, beyond this general behavior, it is difficult to tell much more. The table alone does not reveal whether the relationship is simply linear, or follows a more complex curve. In particular, it does not clearly convey the rate at which the crop yield increases or whether this rate changes over the domain. For such insights, a graphical or algebraic representation is usually more informative.
Graphs
A visual picture of a function can be provided in the form of a graph. The graph of a function is the set of points plotted in a coordinate plane, where for all in the domain of . Plotting data points from a table helps reveal the overall shape and behavior of the function, which may not be immediately apparent from a list of values alone.
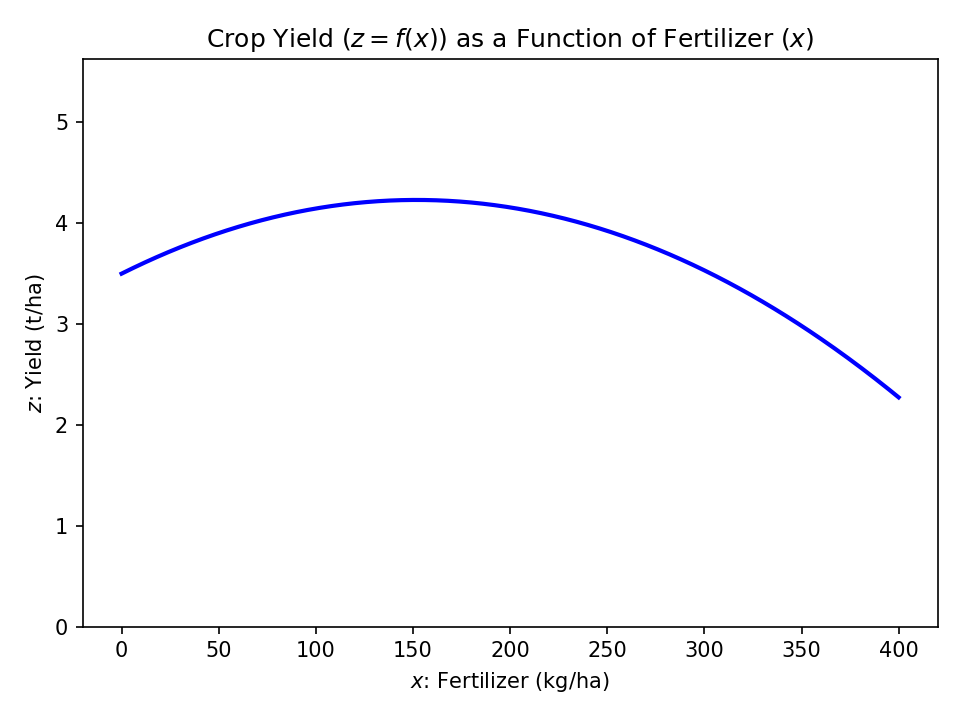
From this graph, we can observe that the function increases with fertilizer (), to a point, but not linearly. The curve appears to flatten and then decrease more sharply, suggesting that the relationship between fertilizer () and yield () is non-linear, possibly polynomial.
Algebraic Formulas
Often, we want more than just individual data points, we want a general rule that allows us to compute the output for any valid input. An algebraic formula provides a compact, symbolic way to describe the relationship between inputs and outputs.
The table and graphs shown above of the crop yield have actually been generated based on the quadratic polynomial:
This expression is not arbitrary, it was obtained from observed data using a method that fits a mathematical function to the measurements. In this case, the polynomial gives an approximation of the relationship between fertilizer amount and crop yield, smoothing out random variations while preserving the overall pattern seen in the data.
Having an algebraic representation allows us to carry out several useful analyses:
- Interpolation: Estimate values between known data points.
- Extrapolation: Predict behavior beyond the observed range, for instance, for very small or large fertilizer amounts ().
- Equation solving: Find input values corresponding to specific outputs, for example solving to determine the corresponding fertilizer amount that yields 4.5 t/ha.
More broadly, models based on algebraic formulas let us describe and explore real-world phenomena: how quantities change together, where growth slows or reverses, and how one variable influences another. Such models form the foundation of mathematical analysis, offering insight into underlying behavior.
To describe these relationships effectively, we must choose a suitable type of function and fit it to the data. In this example, the coefficients of the polynomial were determined using least squares regression, a method that finds the curve that best matches the observed data. Recognizing different classes of functions, such as linear, quadratic, cubic, or exponential, helps us select appropriate models and interpret the types of behavior they represent.
Basic Classes of Functions
Functions can be grouped into different classes based on their algebraic form. Each class has its own properties, domain and range, and characteristic graph shape. In this section, we focus on common basic function classes and describe their general forms (graphical) behavior.
Before exploring specific types, it is useful to note two important features that appear frequently in graphs of functions:
| Feature | Definition | Why It Matters |
|---|---|---|
| Intercepts | Points where the graph crosses the coordinate axes. -intercepts occur when , and the -intercept occurs when . | Represent starting values, equilibrium states, or solutions to problems. |
| Turning Points | Points where the graph changes direction from increasing to decreasing, or vice versa. | Indicate local maxima or minima; used to identify peaks, troughs, or optimal conditions. |
| Asymptotes | Lines that the graph approaches but does not cross (or only crosses at infinity): horizontal, vertical, or oblique. | Describe long-term trends or limits in growth/behavior; mark boundaries. |
Polynomial Functions
Polynomial functions are smooth, continuous curves with no sharp corners or breaks. Their general behavior depends on the degree and the leading coefficient.
Polynomials belong to a broad class of functions that can be written in the general form:
where:
- is a non-negative integer (the degree of the polynomial)
- are real constants
- if
Key characteristics:
- Graph: smooth, continuous curve.
- Intercepts: Up to real -intercepts; always one -intercept at .
- Domain: All real numbers ()
- Range: Depends on the degree and coefficients.
Polynomials are commonly classified based on two characteristics:
- The number of terms
- The degree of the expression
The following tables summarize these classifications with corresponding examples.
| Number of Terms | Name | Example |
|---|---|---|
| Monomial | ||
| Binomial | ||
| Trinomial | ||
| Polynomial |
| Degree | Name | Example |
|---|---|---|
| Constant | ||
| Linear | ||
| Quadratic | ||
| Cubic | ||
| Quartic | ||
| Quintic | ||
| th-degree polynomial |
Linear Functions
A linear function is a polynomial of degree and its graph is a straight line.
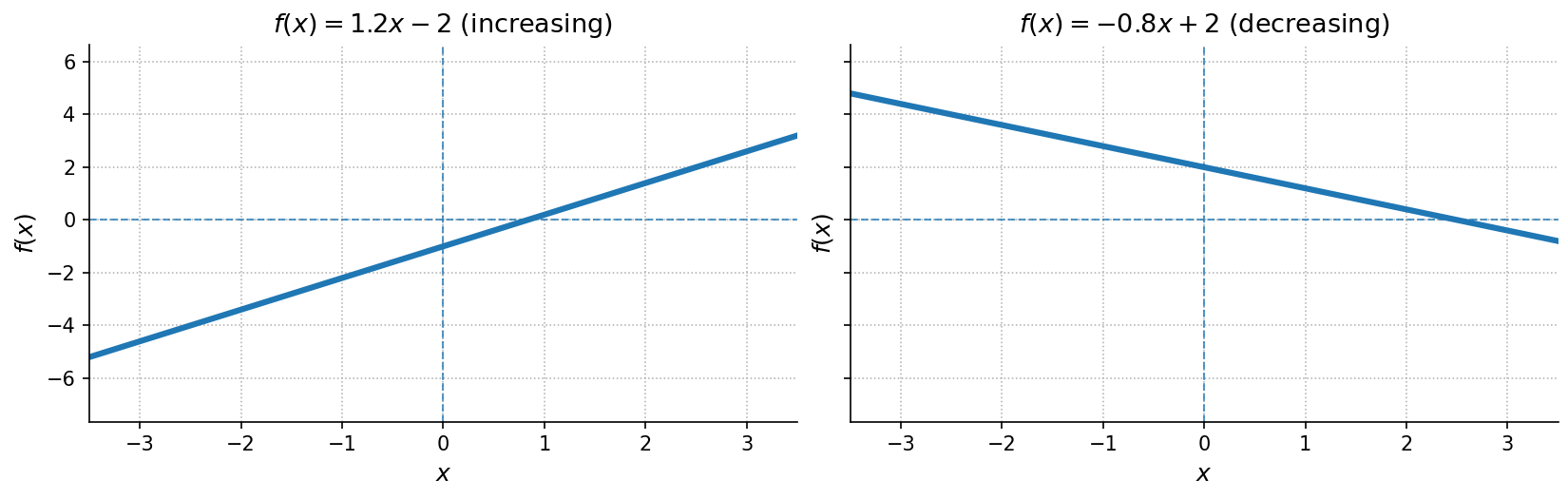
A linear function can be written in the general (slope-intercept) form:
where and are constants. If , it is a polynomial of degree ; if , it simplifies to , which is a constant function (a polynomial of degree 0).
Key characteristics:
- Graph: A straight line with slope .
- If the function is increasing
- If the function is decreasing
- Intercepts:
- -intercept at point
- -intercept at point
- Domain: All real numbers ()
- Range: All real numbers ()
Determine which of the following functions are linear functions:
Answer: is linear (degree 1), while is a constant function (degree 0), and is quadratic (degree 2).
One of the defining characteristics of a line is its slope. The slope describes how a line rises or falls as we move along the -axis, i.e., in other words, it represents the rate of change in for each unit change in .
The slope measures both the steepness and the direction of a line:
- If the slope is positive, the line points upward when moving from left to right
- If the slope is negative, the line points downward when moving from left to right
- If the slope is zero, the line is horizontal
To determine the slope numerically, we compare how much changes relative to . This comparison gives us the ratio of the change in to the change in , leading to the more formal definition below.
Consider a line passing through points and . Let and denote the changes in and , respectively. The slope of the line is:
Now, let us explore how this definition relates to the formula of a linear function. Consider the function:
We already know that the graph of a linear function is a straight line. To find its slope, we can apply the definition above using any two points, i.e., and , on the line. In particular, let us evaluate the function at two convenient points:
- When , we have . This gives us the point:
- When , we have . This gives us the point:
Therefore, substituting the points into the formula for the slope, the slope of this line is:
This shows that the coefficient in the function represents the slope of the line. Hence, every linear function of the form describes a line with slope and -intercept .
This relationship will be revisited in Chapter 8, where the concept of slope forms the basis for defining differentiation.
Quadratic Functions
A quadratic function is a polynomial of degree ; its graph is a parabola.
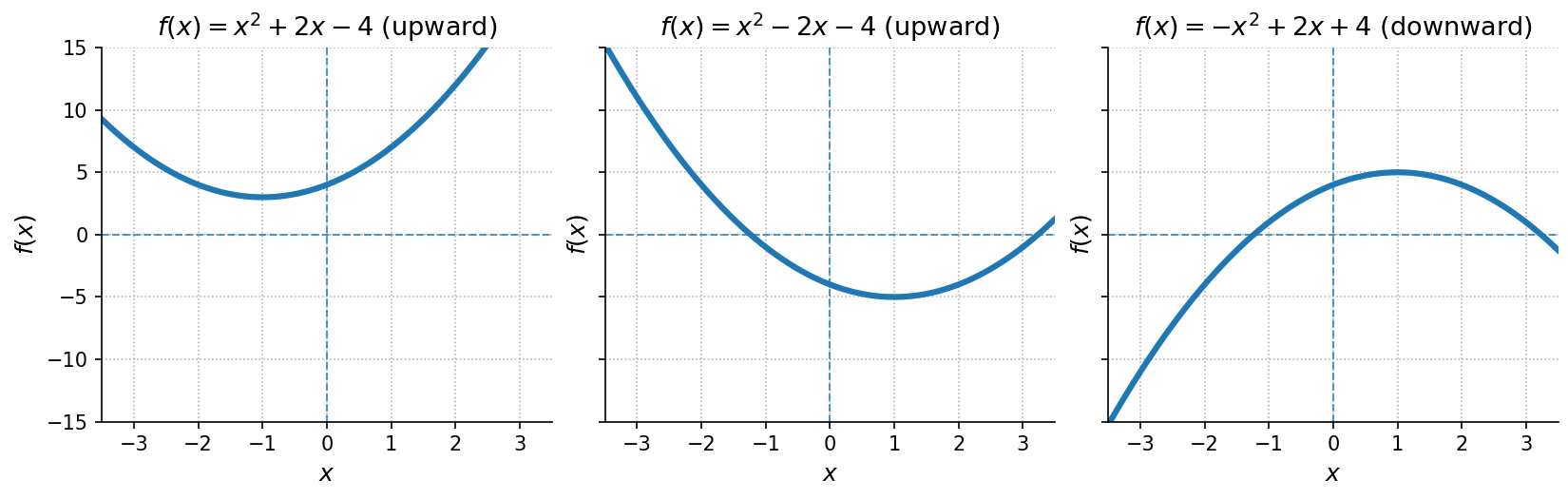
A quadratic function can be written in the general form:
where .
Key characteristics:
- Graph: A parabola.
- If the parabola opens upward
- If the parabola opens downward
- Intercepts: Up to two -intercepts, and exactly one -intercept
- Turning Point: The peak of the graph.
- If it is the lowest point
- If it is the highest point
- Domain: All real numbers ()
- Range:
- If it is
- If it is
Determine which of the following functions are quadratic functions:
Answer: and are quadratic. is cubic.
Exponential Functions
Exponential functions have a constant base raised to a variable exponent.
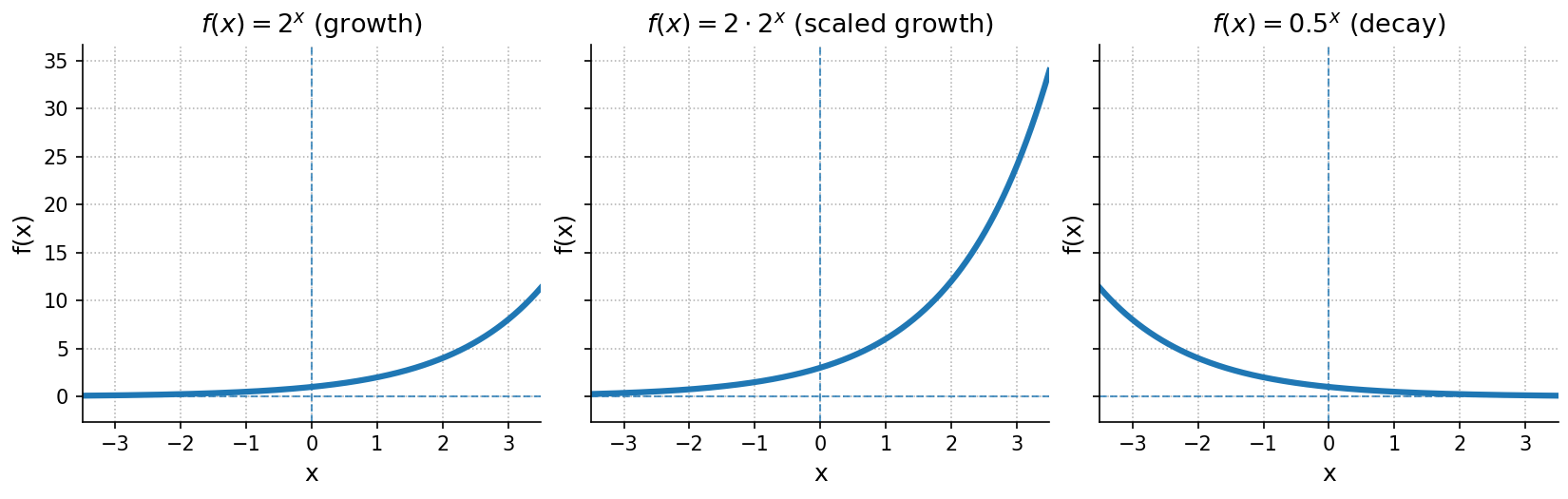
An exponential function can be written in the general form:
where , , and .
Key characteristics:
- Graph:
- If the graph is increasing (growth)
- If the graph is decreasing (decay)
- Asymptote: Horizontal at .
- Domain: All real numbers ()
- Range: if
Determine which of the following functions are exponential functions:
Answer: and are exponential. Here is a power function (a special case of a polynomial).
Logarithmic Function
Logarithmic functions are the inverses of exponential functions.
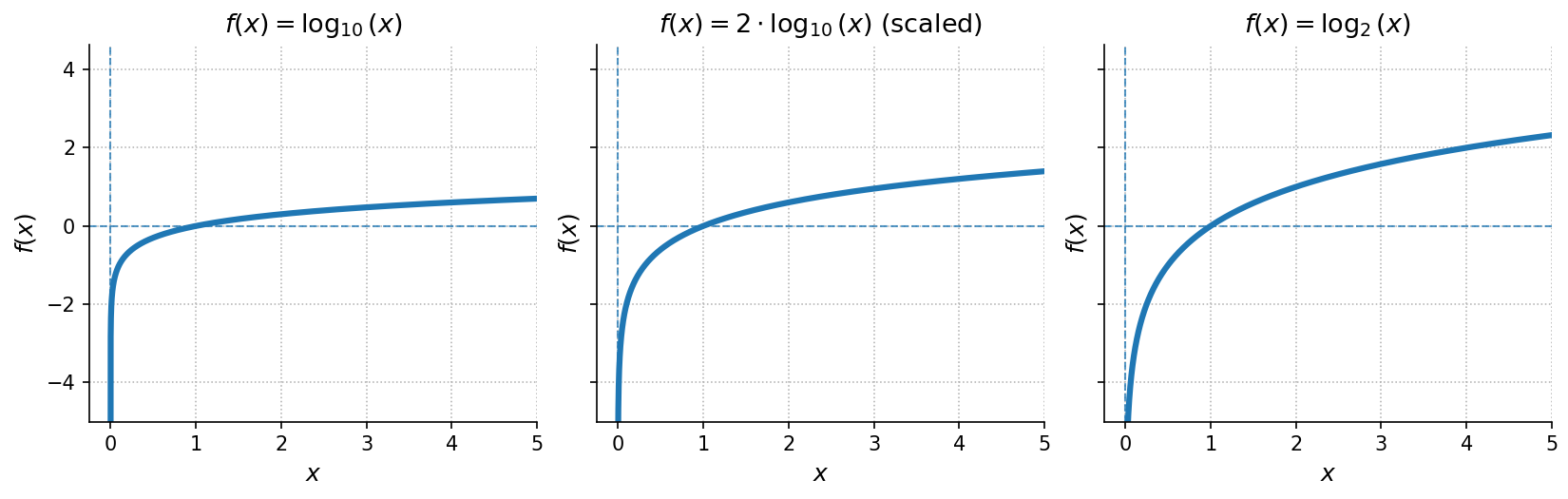
A logarithmic function can be written in the general form:
where , , and .
Key characteristics:
- Graph:
- Passes through if
- Slow, unbounded growth for large
- Asymptote: Vertical at .
- Domain:
- Range: All real numbers ()
Determine which of the following functions are logarithmic functions:
Answer: and are logarithmic. is exponential.
Piecewise-Defined Functions
Not all functions can be described by a single formula. In some cases, different rules apply to different parts of the domain. Such functions are called piecewise-defined functions.
A piecewise-defined function is a function whose rule is given by multiple expressions, each applying to a specific interval (or subset) of the domain. Formally, it can be written as:
where:
- Each defines the function on a subset of the domain
- The subsets are non-overlapping and form the entire domain of
- Each input belongs to exactly one of the subsets , ensuring that the function assigns one unique output for every input
Key characteristics:
- Graph: May be continuous or discontinuous at the boundary points between pieces
- Domain: The union of all subsets
- Range: The union of the output values of all pieces
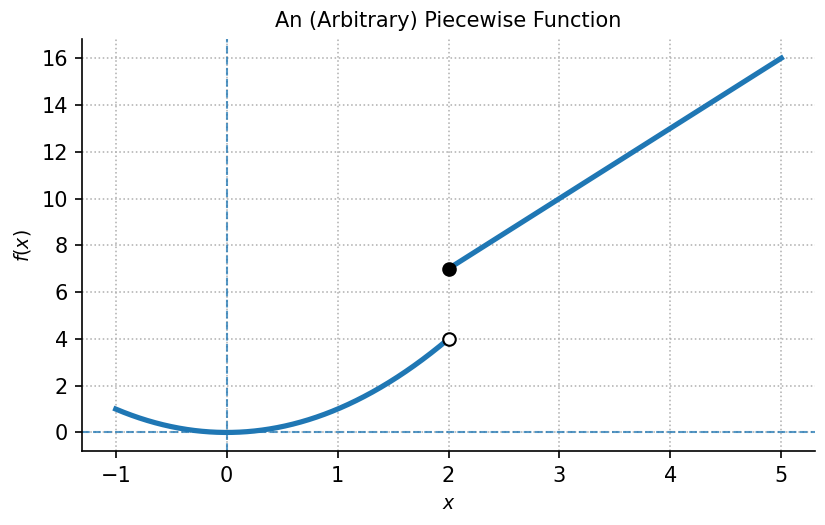
Consider the function defined by
To evaluate a piecewise function, first determine which part of the domain the input belongs to, and then apply the corresponding rule. For instance:
- For , since , use function :
- For , since , use function :
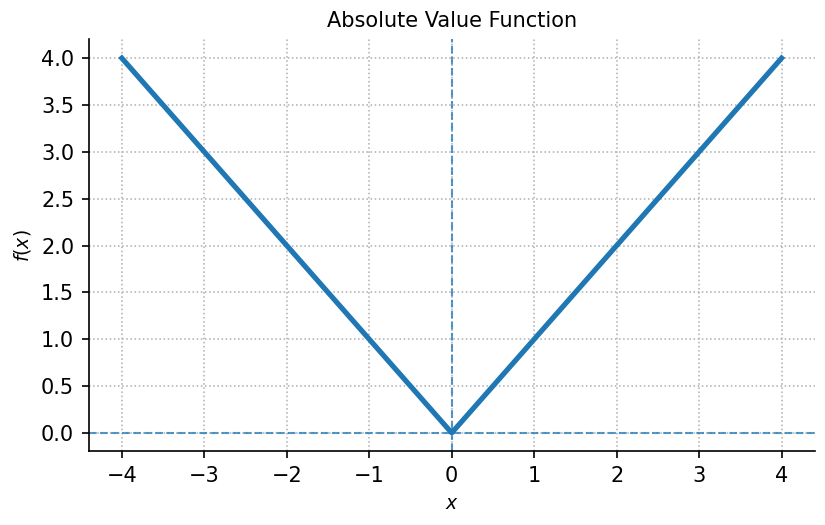
The absolute value function, denoted by , can be expressed as a piecewise-defined function:
Here, positive inputs are unchanged, while negative inputs are reflected across the -axis, ensuring that is always non-negative.
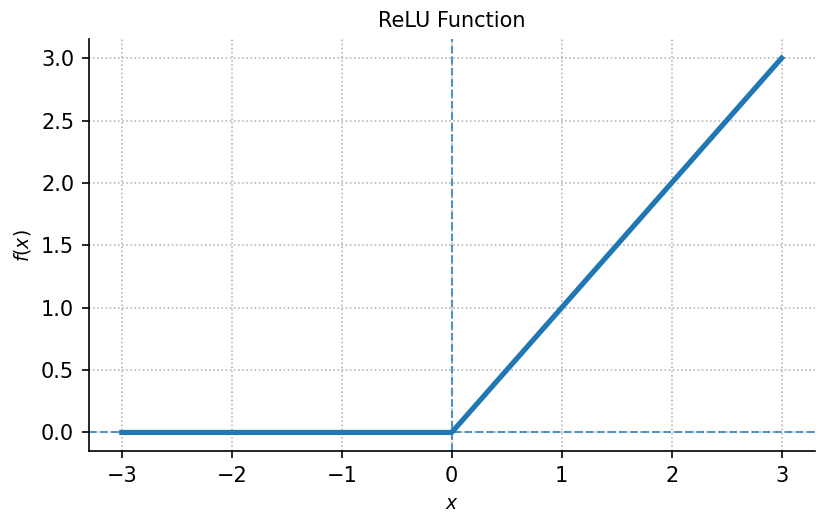
The Rectified Linear Unit (ReLU) is a commonly used activation function in neural networks. It can be expressed as a piecewise-defined function:
The ReLU function outputs the input value itself when it is positive, and zero otherwise. This simple non-linear behavior introduces nonlinearity into neural networks, which is an essential property that allows them to learn complex patterns and relationships in data.
Injective, Surjective, and Bijective Functions
Functions can also be classified based on how they relate elements of their domain to elements of their codomain. While algebraic form determines a function’s shape or formula, mapping properties determine whether the function is one-to-one, onto, or both.
A function is injective (or one-to-one) if it never assigns the same output value to two different inputs. In other words, each output in comes from at most one input in .
More formally, in predicate logic, we can write:
Or in plain words: If two inputs of a function give the same output, then those inputs must be equal.

Let be defined by:
This function is injective because different -values always produce different -values. However, is not injective on since .
A function is surjective (or onto) if every element of the codomain appears as an output of the function. That means the function covers all of , i.e., its range is equal to its codomain.
More formally, in predicate logic, we can write:
Or in plain words: For every possible output value in the codomain, there exists at least one input value in the domain that produces it.

Let be defined by:
For any , there exists , so is surjective. However, from is not surjective because negative -values are never reached.
A function is bijective if it is both injective and surjective. This means that each element of is mapped to a unique element of (injectivity), and every element of is the image of some element of (surjectivity).
More formally, we can write:
Or in plain words: A bijective function establishes a one-to-one correspondence between the sets and , so that nothing is repeated and nothing is left out.

Let be defined by:
The function is bijective because each input produces a unique output (injective) and every real number occurs exactly once as an output (surjective).
Combining Functions
Up to this point, we have explored the basic characteristics of individual functions. We now turn to what happens when functions are combined using standard mathematical operations to create new ones. Just as numbers can be added, subtracted, multiplied, or divided, functions can also be combined in similar ways to form new functions with related behaviors.
In machine learning, the loss function used to train a model often combines several components that measure different aspects of performance.
Suppose we define:
- : The prediction error
- : A regularization term that penalizes overly complex models
Note that may represent several model parameters, but the idea of combining functions, i.e., adding terms that capture different effects, follows the same principle as in the single-variable case.
The resulting loss function balances accuracy (how well predictions match the observed data) with simplicity (how small the model parameters are):
where controls how strongly the regularization term influences the model.
In many real-world models, new relationships are created by combining existing quantities using arithmetic operations.
Suppose we define:
- : the temperature (in °C)
- : the humidity (in %)
A new function can be defined to estimate a heat index (a perceived temperature) as follows:
Here, is obtained by adding a weighted contribution from humidity to the temperature. Such combinations describe how different quantities together determine a result. In this case, both temperature and humidity contribute to the perceived heat.
Suppose and are functions defined on the same domain. The following operations define new functions as shown below:
| Operation | Notation | Definition |
|---|---|---|
| Sum | ||
| Difference | ||
| Product | ||
| Quotient |
Ultimately, these operations let us construct more complex relationships from simpler ones.
In this example, we explore how subtraction and division affect the relationship between two functions. For this purpose, let
We will now find and simplify both and to see how these operations transform the expressions.
First, subtract from :
Then, divide by :
We can see that subtraction and division lead to very different results, i.e., is a quadratic expression, while simplifies to a linear one.
Even though both start from the same and , the way we combine them changes the type of function we obtain.
In this example, we explore how multiplication and subtraction affect the relationship between two functions. For this purpose, let
We will now find and simplify both and to see how these operations transform the expressions.
First, multiply and :
Then, subtract from :
Again, the two resulting functions are very different, i.e., is cubic, while is quadratic.
Function Composition
In the previous examples, we combined functions using arithmetic operations such as addition and multiplication. Now, explore a different kind of combination, i.e., function composition, where the output of one function becomes the input of another.
Function composition allows us to describe multi-step relationships between quantities that depend on one another.
In many real-world situations, one variable influences a second, which in turn affects a third. By composing functions, we can express an entire chain of dependencies as a single mathematical expression.
Suppose we want to calculate how much electricity is used to cool a house on a particular day of the year. The electricity usage depends on the average indoor-outdoor temperature difference, which in turn depends on the average daily temperature outside.
Thus, we have two relationships:
- : Describes the electricity (in kWh) required to maintain a desired indoor temperature for a given outdoor temperature (°C)
- : Describes the average outdoor temperature (°C) on day of the year
For any given day , the electricity use depends on the temperature, which itself depends on the day. We can therefore evaluate at the temperature given by :
This expression represents the electricity used on day . For example, to find the electricity usage on the 10th day of the year, we would first compute , the average temperature on day 10, and then use that value in function , i.e., gives the electricity required to cool the house on the 10th day of the year.
In this case, the function describing temperature is said to be composed with the function describing electricity usage.
The relationship illustrated above can be generalized by defining a new function that represents applying one function after another. For this to be well-defined, the range of the inner function must lie within the domain of the outer function.
This brings us to the formal definition of the composition of functions.
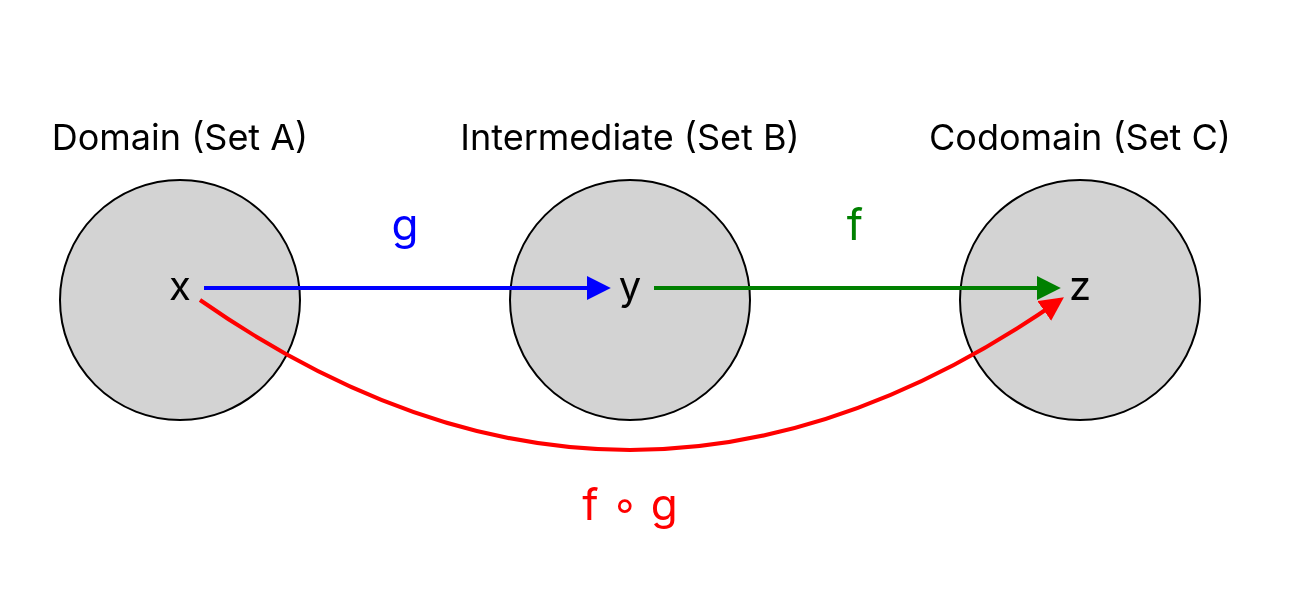
Let and be functions, where the codomain of (the set of its possible outputs) is contained in the domain of . The composition of and , denoted , is the function
defined by
-
Composition is not multiplication:
The composition of two functions is denoted by and defined as
In contrast, the product of two functions is denoted by and defined as
The first applies one function inside another, while the second multiplies their outputs.
-
Composition is not commutative:
In general it is the case that
since
for most functions and . In other words, the order matters because the output of one function becomes the input of the other, and reversing that order usually produces a different intermediate value.
Using the following functions, find both and to determine whether composition is commutative.
First, substitute into :
Next, substitute into :
Because , we see that function composition is not commutative.
Decomposing Functions
The idea of composition naturally leads to its reverse process, i.e., decomposition. While composition builds complex relationships by applying one function after another, decomposition involves expressing a single, complicated function in terms of simpler ones:
This approach makes functions easier to understand and, more importantly, easier to work with. It will play an important role later, particularly in Chapter 8, where recognizing how a function is composed of simpler parts becomes essential for applying the chain rule of differentiation.
Note that a single function may have more than one possible decomposition. In practice, we choose the one that makes the problem easier.
Express as the composition of two simpler functions.
We are looking for functions and such that
To identify these functions, notice that appears inside the square root. This suggests the inner function produces , and the outer function takes the square root of its input. Thus, we can define
We can verify our decomposition by recomposing the functions:
Therefore, with
Express as the composition of two simpler functions.
We are looking for functions and such that
Here, the expression appears inside the denominator. We can treat that as the output of the inner function , and then let the outer function operate on that result. Thus, we can define
We can verify our decomposition by recomposing the functions:
Therefore, with
Chapter Exercises
Chapter 4: Polynomial Factorization
In the previous chapter, we introduced polynomials as a fundamental class of functions that can be written in the general form:
A polynomial consists of terms involving a variable (here, ) raised to non-negative integer powers and multiplied by constant coefficients. Formally, denotes the degree of the polynomial, and are its coefficients, with being the leading coefficient.
In this chapter, we will learn how to manipulate and simplify polynomials in order to better understand their behavior, find their zeros, and analyze their graphs.
A key step in this process is factorization, which allows us to rewrite a polynomial as a product of simpler factors.
Before exploring general methods, recall that certain algebraic identities, introduced in Chapter 2, can be applied directly to polynomials. These identities often enable quick factorizations of specific expressions without the need for more elaborate techniques.
Suppose we want to factor the following polynomial:
This expression simply matches the difference of squares identity, so we apply it directly as follow:
While simple cases like this can be solved using known identities, most polynomial expressions, particularly trinomials, require a more systematic approach. Let us now turn to the process of factoring trinomials.
Factoring Trinomials
One of the most common and useful techniques in algebra is factoring a trinomial, i.e., an expression with three terms, typically of the form:
The goal of factoring is to rewrite the trinomial as a product of two binomials:
Here , , , and are real coefficients chosen so that the product on the right expands back to the original expression on the left-hand side.
This method assumes the coefficients , , and of the trinomial are integers.
To factor a trinomial of the form:
Step 1: Identify the coefficients:
- is the coefficient of
- is the coefficient of
- is the constant term
Step 2: Find two integers such that:
Step 3: Rewrite the middle term as , giving a four-term polynomial:
Step 4: Proceed to factor by grouping (described in the next Algorithm 2).
Once the middle term has been split, the trinomial becomes a four-term polynomial. The next step is to apply the factorization by grouping method, a general strategy for breaking down such polynomials into products of simpler factors.
This method assumes the coefficients , , , and of the four-term polynomial are integers, where and are the integers identified in the previous algorithm.
To factor the four-term polynomial:
Step 1: Group the terms into two pairs:
Step 2: Factor out the greatest common factor (GCF) from each group:
- For , factor out :
- For , factor out : Here, and are constants obtained from factoring each group, and , and are the coefficients in the common binomial.
Step 3: Check for a common binomial factor:
- If both groups contain the same binomial , factor it out:
- Otherwise, if no common binomial appears, try a different grouping or another factoring technique.
While factoring by grouping is a useful technique, it does not always work.
If no common factor (such as a binomial) appears after grouping, the expression cannot be simplified by this method, and other factoring techniques should be considered instead.
In some cases, particularly when the coefficients are irrational, complex, or when no integer factorization exists, no factoring method may succeed. When this occurs, the polynomial is said to be prime, meaning that it cannot be factored further over the number set under consideration (for example, the integers or the real numbers).
Factor the following polynomial using factorization by grouping (Algorithm 2):
Step 1: Group the terms into two pairs to prepare for factoring.
Step 2: Factor out the greatest common factor from each group.
Step 3: Factor out the common binomial.
Factor the following polynomial using factorization by grouping (Algorithm 2):
Step 1: Group the terms into two pairs to prepare for factoring.
Step 2: Factor out the greatest common factor from each group.
Step 3: Factor out the common binomial.
The remaining quadratic can be factored further using the difference of squares identity:
If we substitute this back into the expression, then we get:
Chapter 5: Equation Solving
Equations express the equality of two expressions and are essential tools for modeling and solving real-world problems. While a function describes the relationship between variables, solving an equation means finding the variable values that make the equality true. This section focuses on linear and quadratic equations, highlighting how their solutions, i.e., the roots, connect algebraic methods with geometric interpretation. We will also extend these ideas to equation-solving for other basic classes of functions introduced earlier.
Earlier, we described functions and particular points associated with the graph of a function that are typically of interest due to what they represent. We described - and -intercepts, where:
- The -intercepts are the points at which the output value is zero.
- The -intercept is the point at which the function has an input value of zero.
Analytically, these points can be found by solving:
- -intercepts: solve
- -intercept: solve
Both of these tasks are examples of equation solving, i.e., we set a function equal to a specific value (often zero) and find the corresponding input(s). The process of solving an equation, therefore, has both an algebraic side (manipulating numbers and symbols to isolate the variable) and a geometric side (finding where a graph meets a horizontal or vertical axis).
Using algebraic properties, we "isolate" a particular variable on one side of the equality sign so that we obtain a solution in the form:
where "stuff" can be an expression containing numbers, constants, other variables, and mathematical operators such as addition, subtraction, multiplication, division, square root, and the like.
Solutions to Equations as Roots
The concept of a root is central to solving many types of equations, fundamentally linking algebraic solutions to graphical interpretations.
A root of a function is a point such that .
Graphically, these are the points where the function's graph intersects the -axis (i.e., a root is synonymous with the function's -intercepts).
Any equation of the form can be transformed into the problem of finding the roots of a new function:
This means that solving for the equality of two functions is equivalent to finding the -intercepts of their difference.
Solving Linear Equations
In this section, we illustrate the equation-solving process for the case where the resulting function is linear. In such cases, solving is equivalent to finding the root of the linear function .
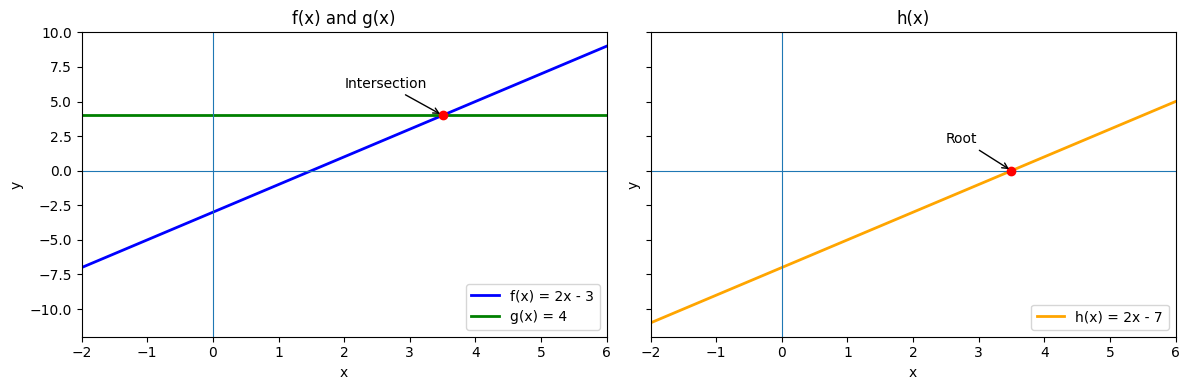
Consider the functions:
Here, is linear and is a constant function.
Finding the intersection of the graphs means determining such that:
We can convert this into a root-finding problem by moving all terms to one side, expressing the equation in the standard form :
Here, the left-hand side can be regarded as a new function . Finding its root is equivalent to solving the original equation:
The solution represents the point where the graphs of and intersect. In terms of the root-finding approach, this is the zero of , i.e., the value of for which crosses the -axis.
Solving Quadratic Equations
In this section, we illustrate the equation-solving process for the case where the resulting difference is quadratic. In such cases, solving is equivalent to finding the root of the quadratic function .
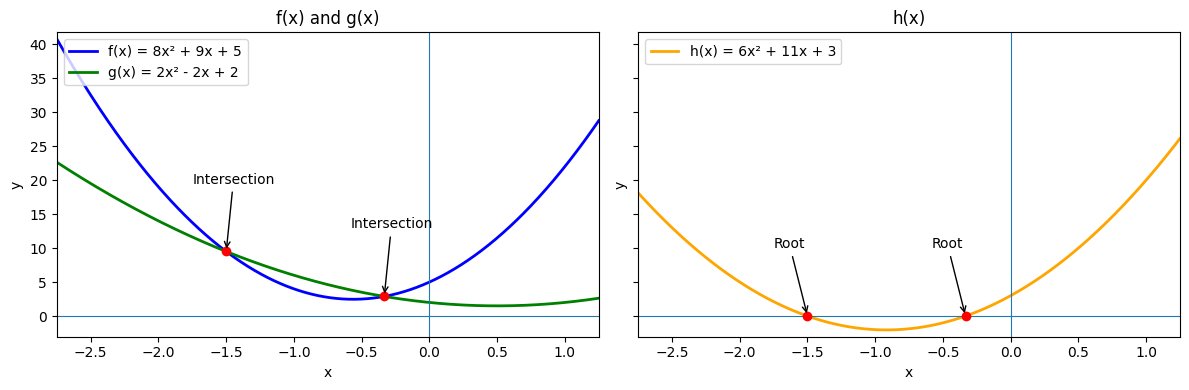
Consider the functions:
Here, and are both quadratic.
Finding the intersection of the graphs means determining such that:
We convert this to a root-finding problem by moving everything to one side:
At this stage, we have reduced the problem to solving a quadratic equation:
There are two standard ways to find its roots:
- By factoring the quadratic expression into a product of two linear factors.
- By applying the quadratic formula, which works even when factoring is not straightforward.
In the examples that follows, we will illustrate both approaches, using the same function .
Solving Via Factorization
Factoring a quadratic expression means expressing it as a product of two linear factors. If this is possible, the zero product property can be applied:
This allows us to solve a quadratic equation by setting each factor equal to zero.
We are given the quadratic polynomial
and want to factorize it using the grouping method, which we learned about in the previous Chapter 4.
The expression contains three terms, but the grouping method requires four. Thus, the first step is to rewrite the trinomial as a four-term polynomial. We can do this using Algorithm 1 from Chapter 4.
Step 1:: Identify coefficients:
- is the coefficient of the higest-order term
- is the coefficient of the second-highest-order term
- is the constant term
Step 2: Find two integers , such that
Choosing and satisfies these conditions since and .
Step 3: Rewrite the middle term using and :
Now we can apply the grouping method as described in Algorithm 2.
Step 1: Group the terms into pairs:
Step 2: Factor out the greatest common factor (GCF) from each group:
Step 3: A Common binomial factor appears:
Finally, we can now apply the zero product property to solve for :
Solving Via The Quadratic Formula
Another way to find the roots of is to apply the quadratic formula.
Consider the quadratic equation:
where . The solutions of this equation is given by the quadratic formula:
The discriminant determines the number of real solutions:
- If : two distinct real solutions.
- If : one real (repeated) solution.
- If : no real solutions.
Note: the symbol in the formula above means that we consider the expression both when the square root positive and negative.
To solve the quardratic equation
we set , , and in the formula:
Hence, we get:
These match the solutions obtained by factoring.
Factorized Form and Roots of a Polynomial
Just as quadratic equations can be expressed in factorized form as
higher-order polynomials can likewise be written as a product of linear factors. This leads us to the following definition.
A polynomial function of degree can be expressed as
where is the leading coefficient and each is a root (or zero) satisfying .
This form reveals several geometric features of the polynomial:
- The number of factors equals the degree of the polynomial
- Each root corresponds to an -intercept of the graph
- The coefficient determines the vertical stretch and orientation of the curve. For example, changing its sign reflects the graph across the -axis.
The following examples illustrate how these properties appear graphically.
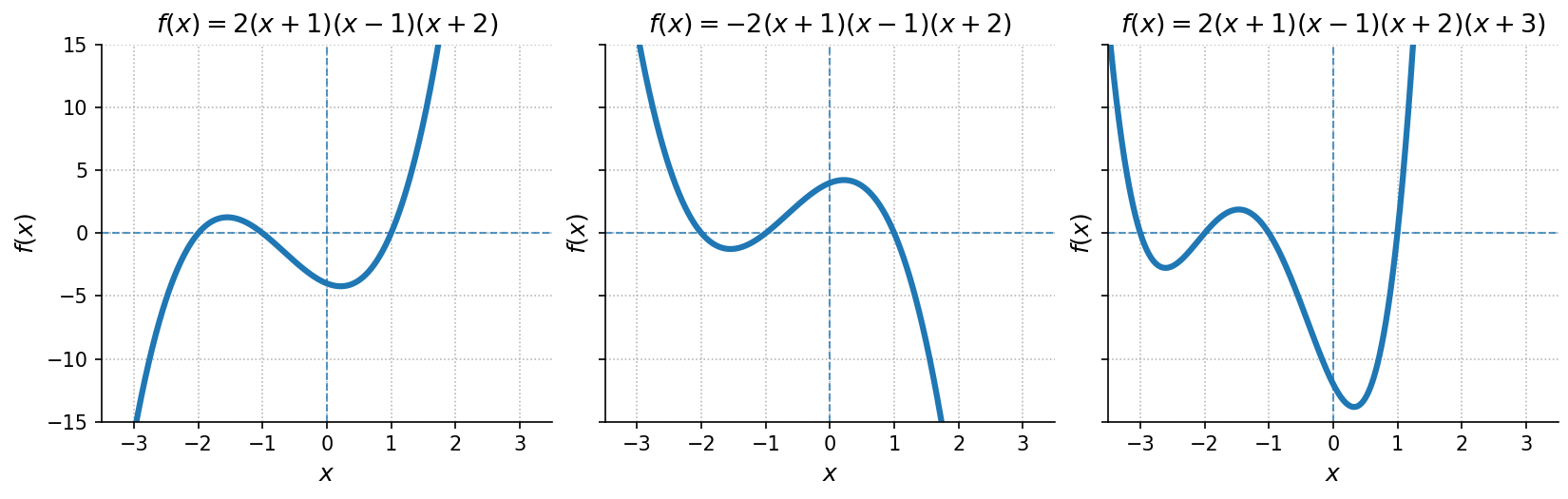
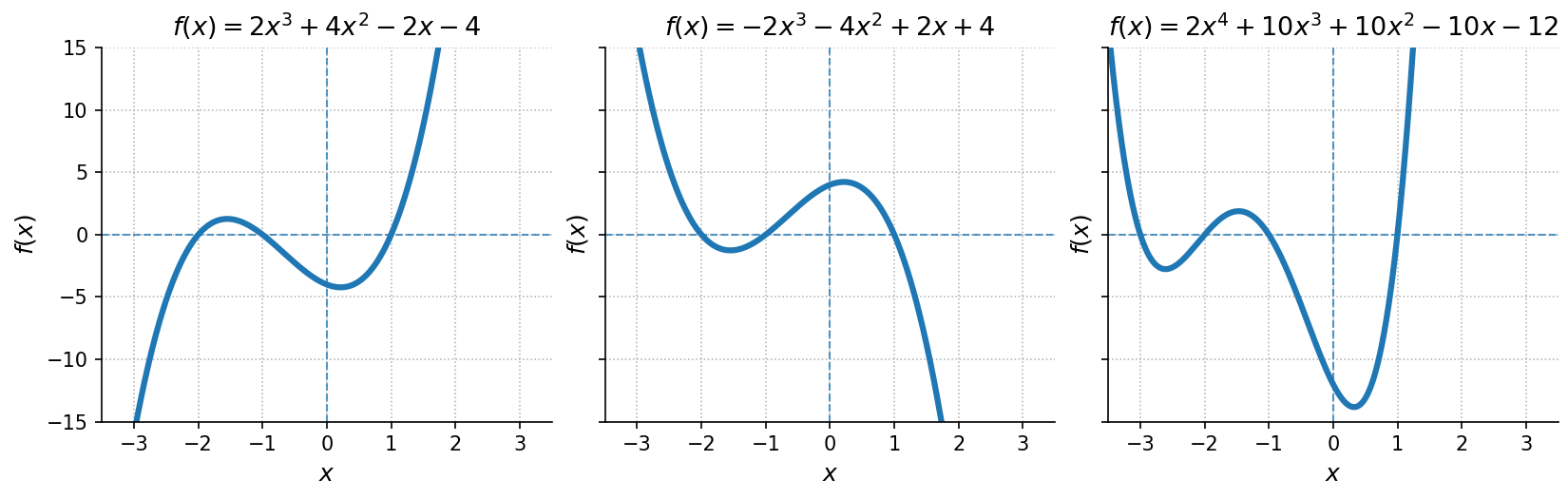
Consider the first polynomial in the plot:
This function has three linear factors, so the polynomial is of degree three. The zeros, listed in the order they appear in the algebraic expression, are , , and . At each of these points, one factor becomes zero, defining an -intercept where the graph meets the -axis.
Now look at the second polynomial in the plot:
The only difference is the sign of the leading coefficient. Changing it from to reflects the entire graph across the -axis, while the zeros remain in the same order and at the same positions.
Finally, consider the third polynomial in the plot:
Here we have four linear factors, so the polynomial is of degree four. The zeros, again listed in the order of the factors, are , , , and . As before, each root defines an -intercept where the graph meets the -axis.
The Sign and Behavior of a Function Around Its Roots
Finding the roots of a function does more than just tell us where it intercepts the -axis: It also reveals where the function takes on positive or negative values.
By analyzing the sign of between its roots, we can determine on which intervals the function lies above or below the -axis, and thus describe its overall behavior.
The concepts of a function being Increasing on an Interval and Decreasing on an Interval further describe how the function behaves within those intervals, i.e., whether it rises or falls as changes.
These ideas are closely related: once the roots are known and the sign of is determined, examining whether the function is increasing or decreasing helps us describe its overall shape and how it varies. Together, they provide a more complete picture of a function’s behavior, even without graphing it.
Let be a real-valued function. We say that:
- is positive on an interval if for all in that interval.
- is negative on an interval if for all in that interval.
Graphically, this corresponds to whether the graph of the function lies above (positive) or below (negative) the -axis.
Because the sign of a function can only change at its roots, we can use the roots to divide the real line into intervals and then determine the sign of within each one.
For our quadratic function , we found earlier, that the roots are:
These roots divide the real line into three intervals:
By testing a single point in each interval (for instance, ), we find:
| Interval | Test Value | Sign of | Behavior |
|---|---|---|---|
| is positive | |||
| is negative | |||
| is positive |
Inverse Functions
When solving an equation of the form:
we often want a general way to determine the input for any output value (in 's codomain). For some functions, it is possible to find another function that "reverses" the mapping performed by . This reversing function is called the inverse function.
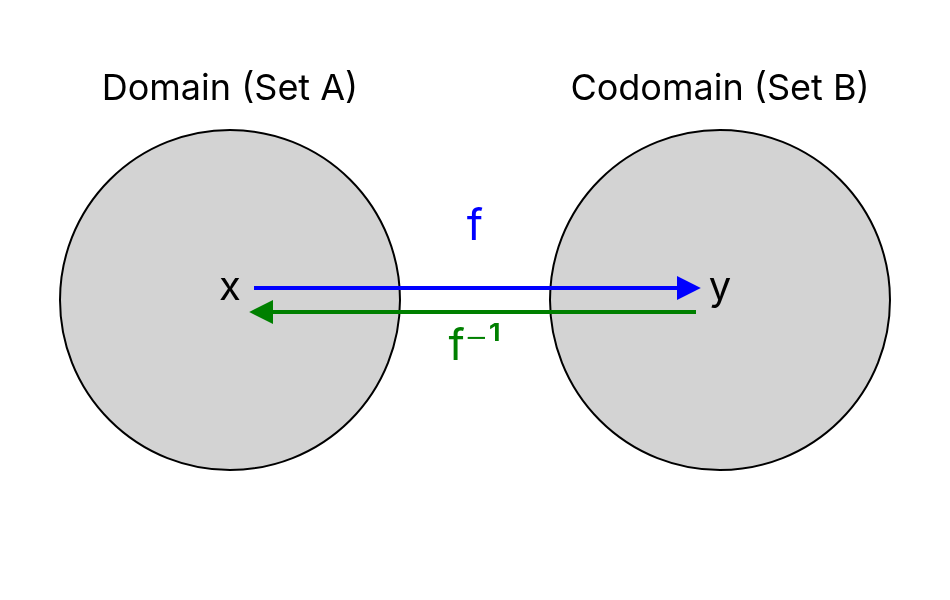
Let be a function. An inverse function satisfies:
for all and . This means that applying followed by (or vice versa) brings us back to the original value.
The inverse function essentially allows us to solve equations by applying to both sides:
However, not every function has an inverse. Understanding when an inverse exists is thus essential.
-
A function has an inverse only if it is bijective, that is:
- Injective (one-to-one): no two inputs give the same output.
- Surjective (onto): every element of the codomain is produced by some input.
Otherwise, the mapping cannot be uniquely reversed.
-
The notation represents the inverse function, not the reciprocal: The superscript indicates reversal of the mapping, not exponentiation.
The composition of a function and its inverse returns the identity function on the respective domains:
That is, the inverse of a function reverses the domain and codomain of . Graphically, the inverse corresponds to reflecting the graph of across the line .
Suppose is defined by
To find , solve for in terms of :
This expression tells us how to recover from a given output , so:
Now, suppose we want to solve the equation:
To determine for which value of the function is euqal to , we need to isolate on one side of the equality sign. Since we have already found the inverse of the function we can achieve this by applying to both sides:
Since reverses the action of , the left-hand side simplifies to :
In general, this is the reason for applying to both sides: it "undoes" on the side of the equality containing , essentially leaving alone.
Consider the function in the earlier example, along with its inverse:
We can always check our work, by verifying the inverse properties, that is:
Doing so, we indeed see that:
Moreover, we see that:
Thus, and are true inverses: each "undoes" the other's operation. In particular, multiplies by and adds , while subtracts and divides by , reversing the steps in the opposite order.
Common Inverses
Each of the examples given below show frequently used function-inverse pairs with their domains and ranges.
Logarithm Rules
Since logarithms are inverse functions of exponentials, each rule in the table above can be derived directly from the exponent rules defined in Chapter 5.
| Function | Inverse | Domain of | Range of |
|---|---|---|---|
| , | |||
| , | |||
| , odd | |||
| , even | (principal root) | ||
| , | |||
| , |
Logarithm Rules
For , , , and , the most important rules are given in the following table.
| Rule | Formula | Description |
|---|---|---|
| Product Rule | The logarithm of a product equals the sum of the logarithms. | |
| Quotient Rule | The logarithm of a quotient equals the difference of the logarithms. | |
| Power Rule | A power in the argument becomes a multiplier in front of the logarithm. | |
| Logarithm of 1 | Any base raised to the power 0 equals 1. | |
| Logarithm of the Base | Any base raised to the power 1 equals itself. | |
| Inverse Property | Exponential and logarithmic functions cancel each other. | |
| Natural Log of | Since means . | |
| Change of Base | Converts a logarithm from one base to another. |
Note: The natural logarithm is simply , where is Euler's number. All these rules work the same way for as for for any base , .
Since logarithms are inverse functions of exponentials, each rule in the table above can be derived directly from the exponent rules defined in Chapter 5.
Solving Non-Linear Equations
Many equations in mathematics involve non-linear functions such as exponentials and logarithms. The solving principles remain the same: we transform the equation into an equivalent one where the variable of interest is isolated, checking that the solution satisfies any domain restrictions.
A common strategy for solving these equations is to undo an operation using its inverse. In this context, we can make direct use of the inverse function pairs introduced earlier. In particular, when the variable appears in an exponent, we apply a logarithm to both sides, and when it appears inside a logarithm, we apply an exponential.
Solve the equation for . Assume that , as the logarithm otherwise is not defined. We obtain:
Determining Whether a Relation is a Function
Graphically
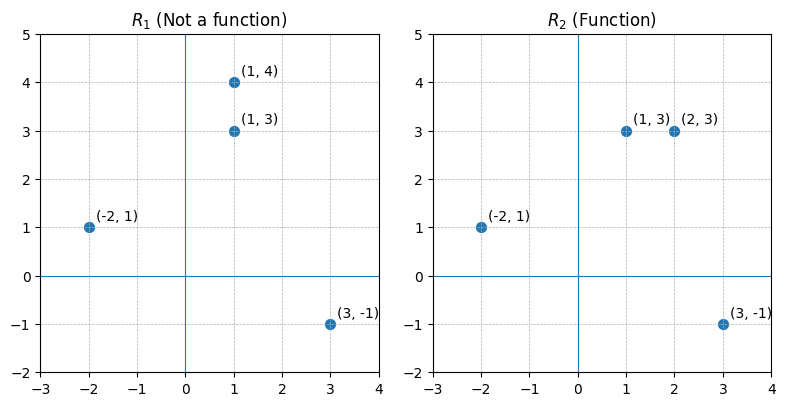
A relation in which each -coordinate is matched with exactly one -coordinate is said to describe as a function of . This also means that, if the same -coordinate is associated with two different -coordinates, then the relation is not a function.
Which of the following relations descbribe as a function of ?
Inspecting the points of reveals that the -coordinate is matched with two different -coordinates: Namely and . Hence in , y is not a function of . On the other hand, every -coordinate in occurs only once which means each -coordinate has only one corresponding -coordinate. So, does represent as a function of . We can verify this graphically as well:
The Vertical Line Test
More generally, this also leads to the vertical line test, which is a quick graphical method to decide whether a relation is a function.
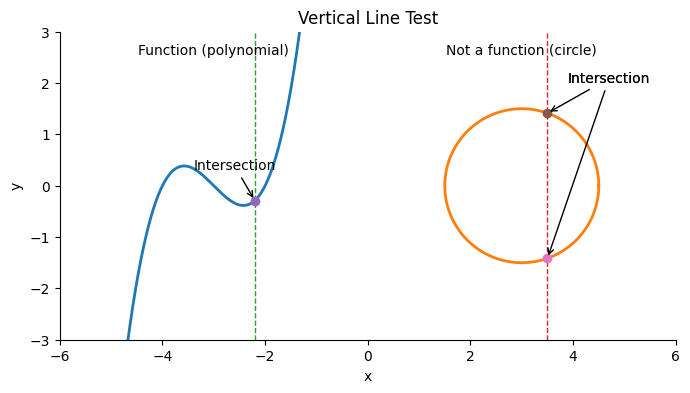
A relation is a function if and only if every vertical line intersects its graph at most once.
If a vertical line intersects more than once, the relation assigns more than one output to the same input thus violating the definition of a function.
It is important to note that equations can describe valid relationships—like the shape of a circle—but do not define a function. Recognizing this helps us understand both the limits of function notation and the situations where we need use other representations (such as parametric or implicit forms).
Algebraically
We can also check whether an equation defines a function by solving for one variable in terms of the other. If solving produces more than one output value for the same input, then the relation is not a function.
Does the equation represent a function with as input and as output? If so, express the relationship as a function .
Solution:
First we subtract from both sides:
We now try to solve for in this equation:
so, and . We get two outputs corresponding to the same input, so this relationship cannot be represented as a single function .
Chapter 5: Multivariable Functions
So far, we have focused on functions of a single variable, where each input is a single number and each output is a single number . Many situations, however, involve relationships between more than one independent variable.
For example:
- The temperature at a given location may depend on both the latitude and the longitude
- The profit of a company may depend on both the number of units sold and the unit price
When working with two independent variables, say and , it is natural to consider ordered pairs , where each coordinate is a real number. The set of all such pairs is denoted by and is often thought of as the Cartesian plane. Similarly, ordered triples form , which we interpret as three-dimensional space. More generally, denotes the set of all ordered -tuples , where each coordinate is a real number.
A real-valued function of variables is a rule that assigns to each input
exactly one real number .
This is written as:
- The set is called the domain of and contains all valid inputs (points in ) for which is defined.
- The range (or image) of is the set of all actual outputs:
Visualizing Functions of Multiple Variables
When , the graph of a function can be drawn in a two-dimensional coordinate system. When , we can represent the graph in three dimensions, with the third axis showing the value of . For , it is no longer possible to directly visualize the graph in physical space, but other techniques, such as level curves and function traces, can be used to represent the function’s behavior.
To illustrate these ideas, we extend the crop yield model we studied earlier, in Chapter 3, to include additional factors.
Example: Extended Crop Yield Model
In reality, crop yield depends on more than just fertilizer amount. Another important factor is rainfall, denoted by (in millimeters over a growing season of about days, i.e., months). We now model crop yield as a function of two variables:
Here, assigns a real-valued yield to each ordered pair within a suitable domain (e.g., kg/ha of fertilizer and mm of rainfall).
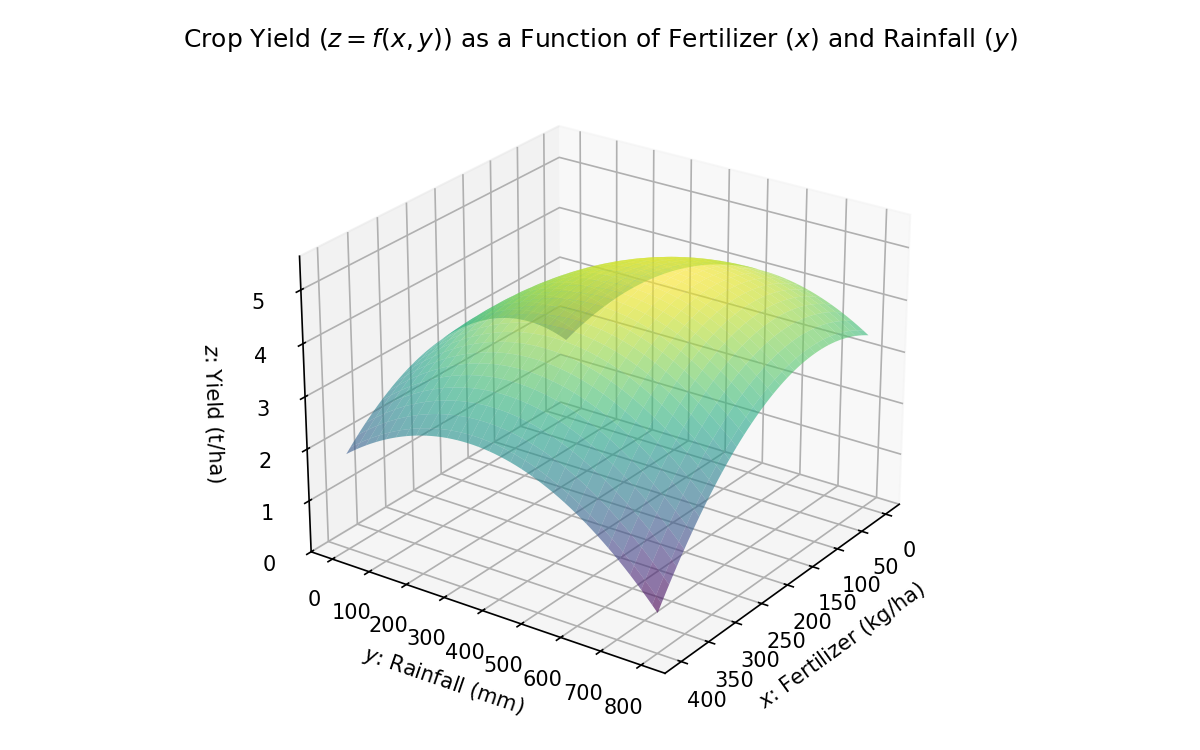
Because depends on two variables, its graph lives in three dimensions: the horizontal plane represents (fertilizer) and (rainfall), while the vertical axis represents (yield). Although 3D graphs are possible, they can be difficult to interpret—especially for decision-making—so we often use level curves and function traces instead.
Level Curves or Contours
Level curves show where the function has the same value, making it easier to identify trade-offs and regions of interest.
For a function of two variables , a level curve (or contour) is the set of all points in the domain where the function takes a fixed constant value :
In the -plane, a level curve connects all points where produces the same output.
In the crop yield model, a level curve for represents all combinations of fertilizer and rainfall that yield the same harvest.
For a fixed yield , the level curve is:
For example, the level curve for shows all fertilizer-rainfall combinations producing a yield of tonnes per hectare.
From a contour plot, we can answer questions such as:
- "If I want t/ha, how can I trade fertilizer for rainfall?"
- "Where is the optimal combination of fertilizer and rainfall for maximum yield?"
Level curves are especially useful for visualizing decision boundaries and trade-offs when multiple factors influence an outcome.
Function Traces
Function traces help us examine cross-sections of the surface by fixing one variable and varying the other.
For , a trace is obtained by fixing one variable and letting the other vary:
- Trace in the -direction: Fix and consider
This curve lies in the vertical plane parallel to the -plane.
- Trace in the -direction: Fix and consider
This curve lies in the vertical plane parallel to the -plane.
For example:
-
Fix fertilizer at kg/ha and vary rainfall: The trace shows how yield changes with rainfall for that fertilizer level.
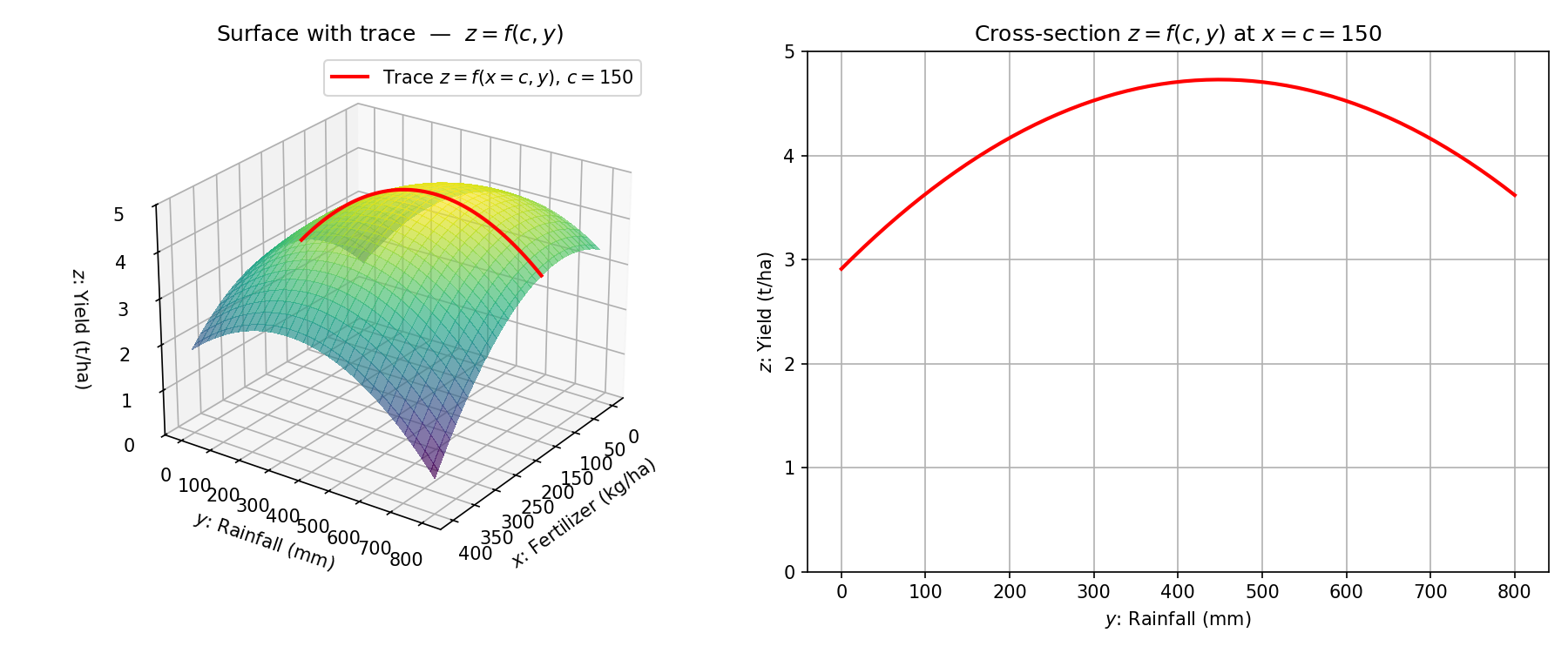
Trace: Yield vs Rainfall with Fertilizer fixed at kg/ha. -
Fix rainfall at mm and vary fertilizer: The trace shows how yield changes with fertilizer for that rainfall level.
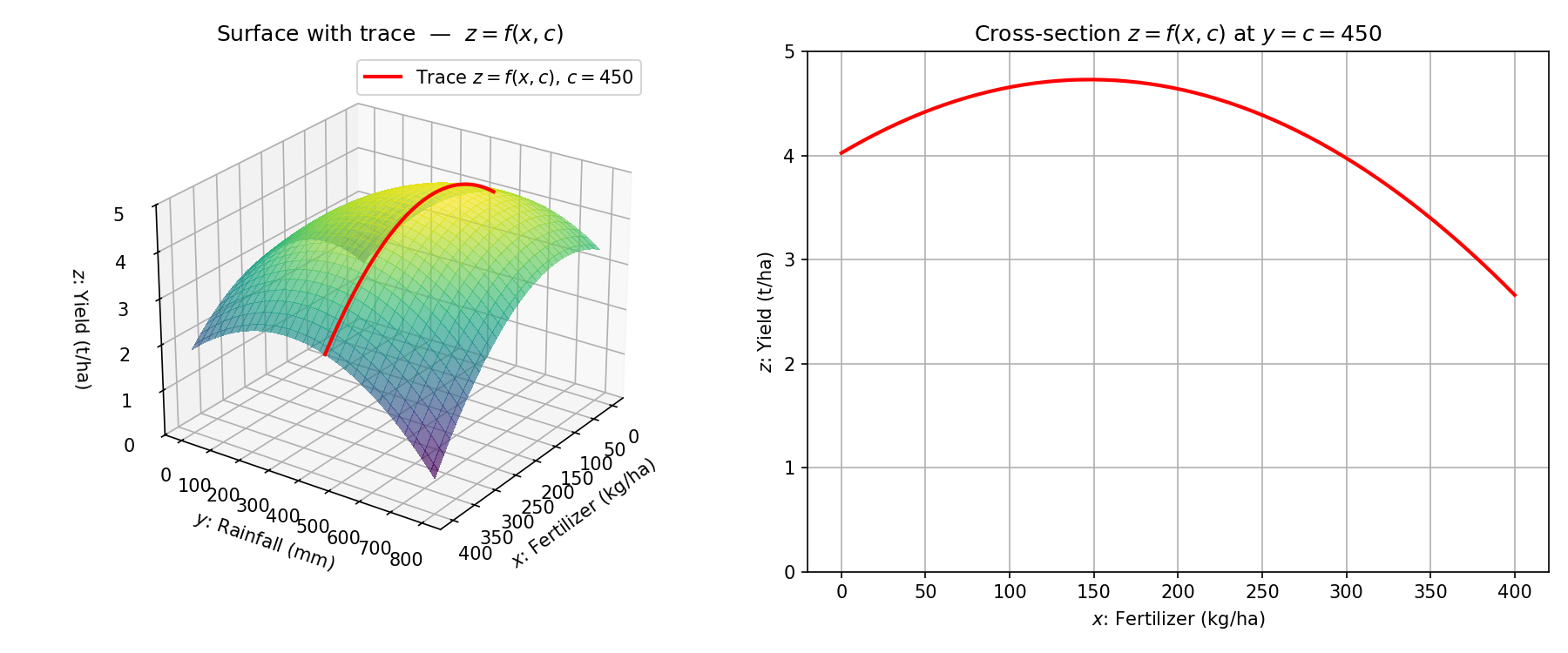
Trace: Yield vs Fertilizer with Rainfall fixed at mm.
From these traces, we can identify tipping points, such as the fertilizer amount beyond which adding more no longer increases yield.
Computing Level Curves and Traces
The task of finding level curves and traces reduces to solving equations. The algebraic and graphical techniques are the same as those used for curves in two dimensions, but here they are applied to cross-sections and slices of surfaces.
Chapter 6: Limits
Limits & Continuity
The concept of a limit concerns the value that a function approaches as its input gets closer to a particular point. Importantly, what happens exactly at that point is not what matters, instead, we focus on what happens around the point.
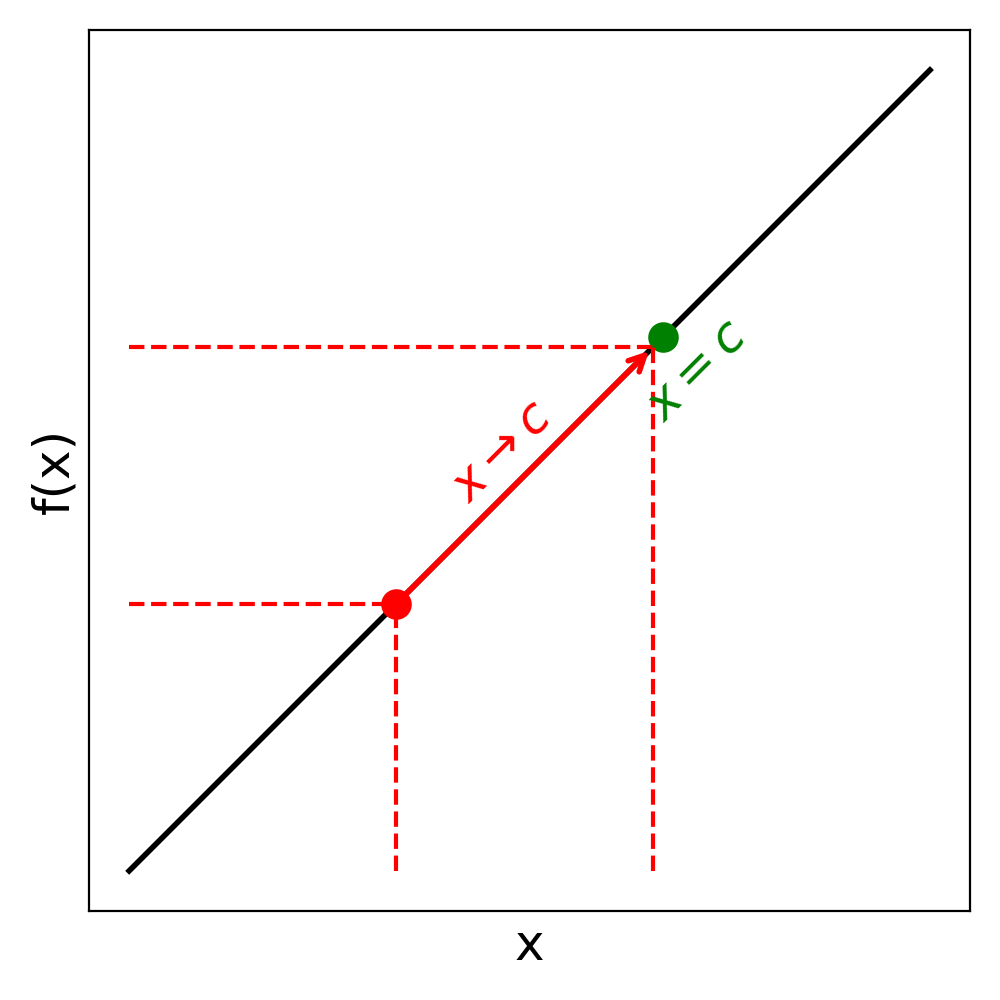
Understanding the concept of a limit is fundamental as it allows us to study the continuity of functions, a property describing whether a function behaves smoothly without abrupt jumps or breaks. Furthermore, limits are the foundation for defining derivatives, which describe rates of change.
To illustrate this and build an intuitive understanding of the concept of limit, consider the function and its corresponding graph:
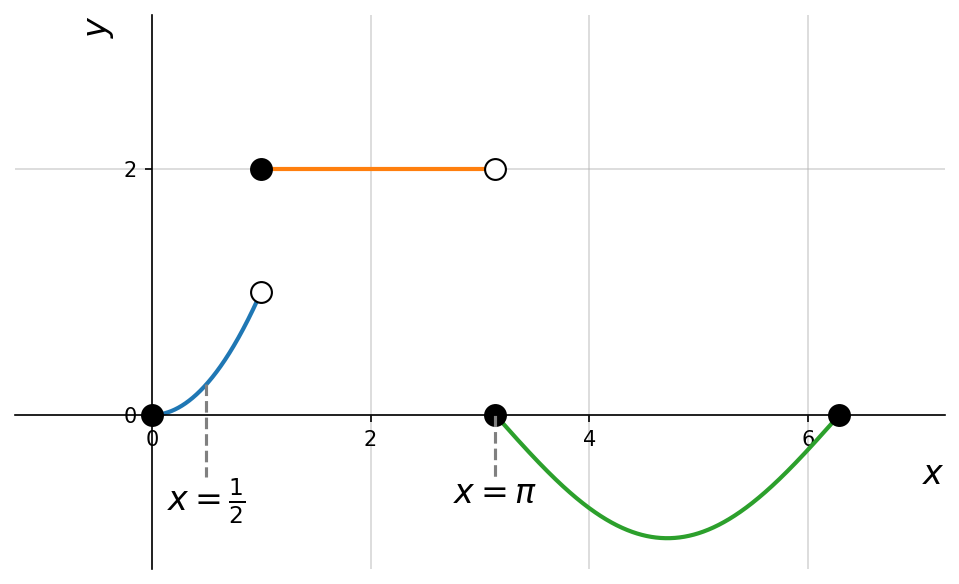
Let us consider the limit of as . This means that we look at values of for in some small interval around . In this case, this corresponds to examining the function on the interval . If we look the graph of this function, we can see that as approaches from either the left or the right, the value of approaches .
Therefore, the limit of as can be expressed symbolically as:
This example illustrates the basic idea behind limits. We now state this idea in more general terms.
Let be a function defined on an open interval containing (with the possible exception of itself). Let be a real number. If all values of the function approach the real number as the values of approach the number , then we say that the limit of as approaches is .
In words, as gets closer to , gets closer and stays close to . Symbolically, we express this idea as
if and only if
Here means approaching from the right (positive direction) and means approaching from the left (negative direction).
Not every function has a limit at every point. A limit may fail to exist for several reasons. To illustrate this, we return to our earlier example and now consider and . At each of these points, the left-hand and right-hand limits differ:
Since these one-sided limits are not equal, does not exist. The same reasoning applies at .
Another way a limit can fail to exist is if the function grows without bound, for example:
As increases, grows without limit, so it does not approach a finite value. We may write as , but the limit does not exist in the finite sense.
Discontinuity
A discontinuity is a point where the function’s value changes abruptly. In our first example, has discontinuities at and because the limits at these points do not exist.
Consider the function shown below, where has jumps at and .
At , the one-sided limits are different:
Because the left-hand and right-hand limits do not agree,
the two-sided limit does not exist.
Therefore, has a jump discontinuity at .
However, discontinuity does not always mean the limit fails to exist. For instance, consider the following example.
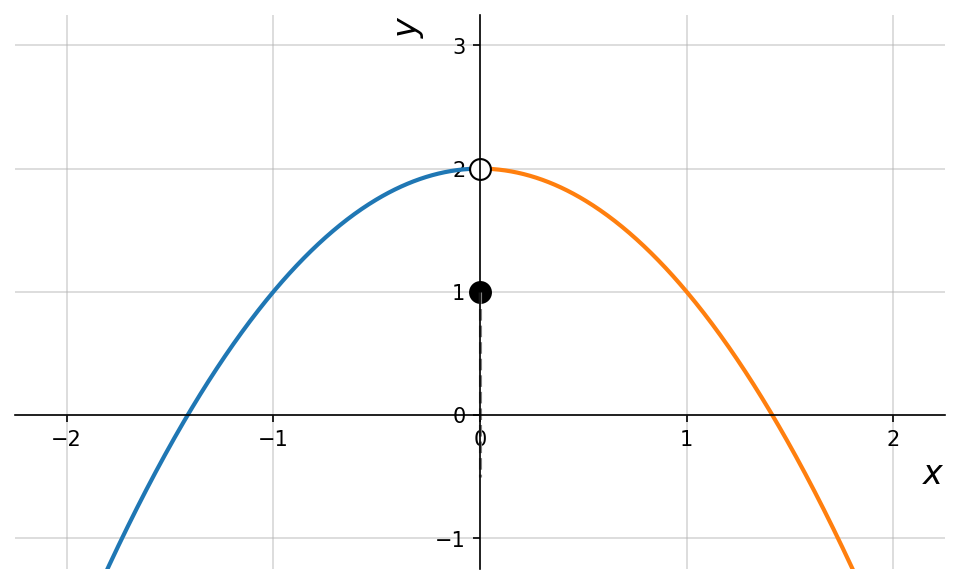
Looking at the graph, it is clear that despite , the actual function value is . In this case, we say that is discontinuous at .
Continuity
The discussion about when limits exist and do not exist, leads us to the following definition.
Let be a function, where is the domain of .
The function is said to be continuous at a point if
That is, as approaches , the value of approaches the same number that actually takes at .
Breaking this definition into its essential parts:
-
The limit exists:
The left-hand and right-hand limits of at are equal.
In symbols,This ensures that approaches a single, well-defined value near .
-
The function value is defined:
The point exists, meaning that belongs to the domain .
Without a defined value at , the concept of continuity cannot apply. -
The limit equals the function value:
The value that approaches near is exactly the same as the value it takes at :This guarantees there is no jump or gap in the function’s behavior at that point.
If is continuous at every point , then we say that is continuous on .
Continuity can therefore be viewed as a local property at each point, which extends to a global property when it holds throughout the entire domain.
In practice, most functions we encounter (such as polynomial, exponential, logarithmic, and trigonometric functions) are continuous on the domains we care about.
Consider the function
We want to determine whether is continuous at .
-
The limit exists:
Since both one-sided limits are equal, the limit exists and equals 2. The condition is satisfied.
-
The function value is defined:
The function has a defined value at . The condition is satisfied.
-
The limit equals the function value:
The limit and the function value are not equal. The condition is not satisfied.
Since the third condition fails, is not continuous at .
Limit Laws
In an earlier chapter, we saw how to combine two functions using arithmetic operations. The table below shows the corresponding rules for limits, assuming both and exist.
| Operation | Limit Law |
|---|---|
| Constant Multiple | |
| Sum/Difference | |
| Product | |
| Quotient |
Determine
- Split into two limits (use the difference law):
- Evaluate each part directly (direct substitution):
Determine
- Check direct substitution (does not work!):
- Factor numerator and cancel the common factor:
- Evaluate the expression (direct subsitution):
Chapter Exercise
Chapter 7: Differentiation
Differentiation
Differentiation is the process of finding the derivative of a function, which tells us the slope of the function at a single point on its graph.
In an earlier chapter, we defined the slope in the context of a linear function. To extend this concept to more general functions, we first define secant lines (slopes over an interval) and then tangent lines (slopes at a single point). These ideas allow us to quantify how a function changes.
Secant & Tangent Lines
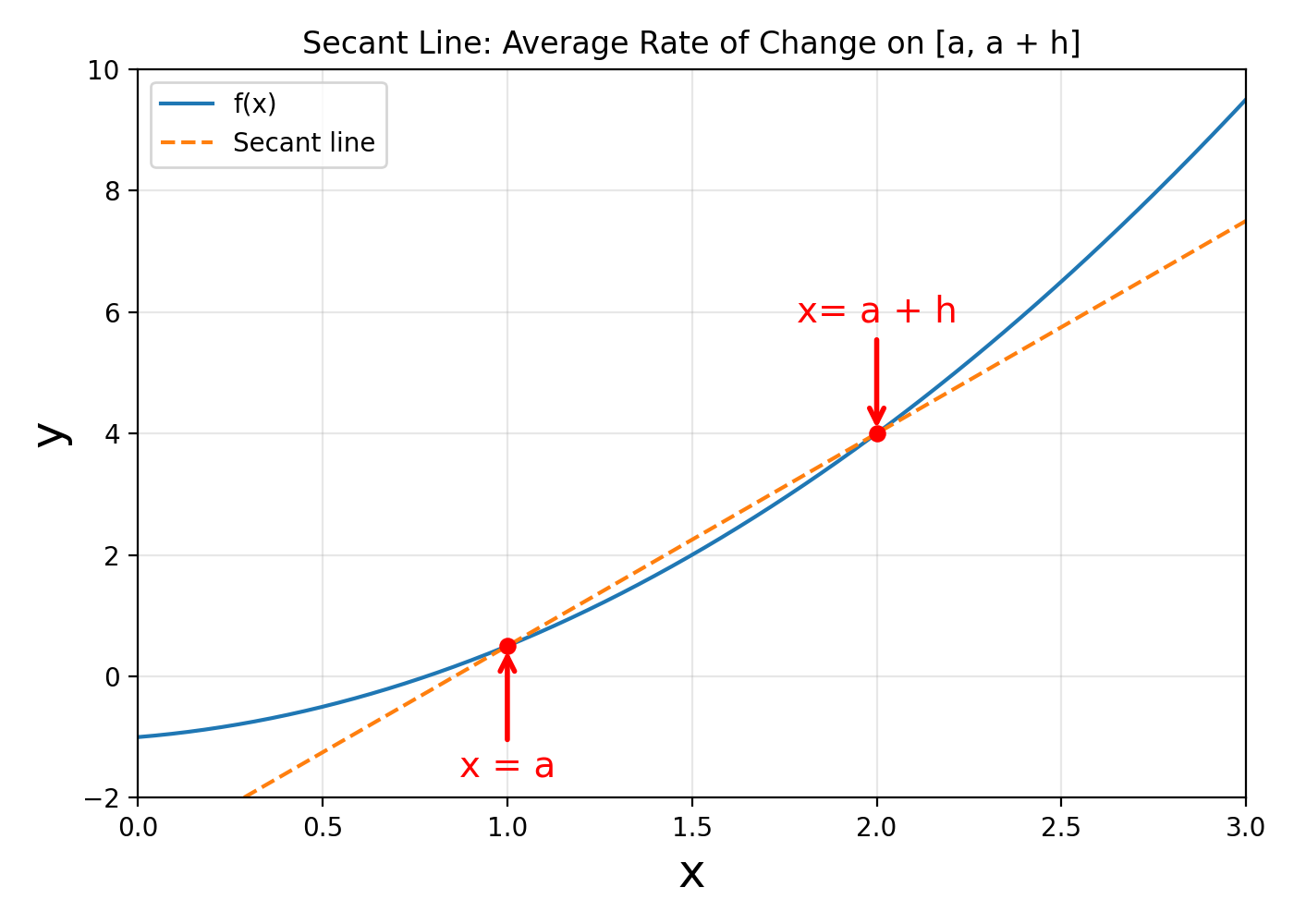
The slope of a secant line to a function at a point gives an average rate of change of a function between and a nearby point.
To compute it, we pick a value of close to , say (where ), and draw a line through the points , and . The slope of this line is:
Let be a function defined on an interval containing . If and , the slope of the secant line is:
This expression is also called the difference quotient.
Let be a function defined in an open interval containing . The tangent line to at is the line passing through with slope:
provided this limit exists.
The Derivative of a Function
Let be a function. The derivative of at is:
provided the limit exists. If the limit exists for all , we say that is differentiable on .
Note that instead of writing , we can also write or . All three expressions denote the derivative of with respect to .
The prime notation is concise and often used in basic calculus or when the variable is clear from context.
The Leibniz notation , on the other hand, emphasizes the operation of differentiation and explicitly indicates the variable, making it useful in contexts with, e.g., several variables or when applying rules like the chain rule.
Note that instead of writing we sometimes write or , i.e., these expressions are equivalent, but ...
Consider the linear function . For any . We compute the derivative of the function, as follows:
This makes sense, as a linear function is a straight line with constant slope.
Consider the quadratic function , for any . We compute the derivative of the function, using the limit laws, as follows:
Common Derivatives
Below is a table of some of the most frequently used derivatives. Here , , and .
| Function | Derivative | Notes |
|---|---|---|
| Constant rule | ||
| Power rule | ||
| - | ||
| - | ||
| - |
Using the rules in the table, compute the derivative of the function .
Letting and , we get from the table of derivatives that and . The product rule then gives
Common Differentiation Rules
Just like for limits, there are certain rules that we can apply when differentiating functions. In this context, let and be differentiable functions on an interval, with . The following rules then hold:
| Rule | Formula | Name |
|---|---|---|
| Sum/Difference | Sum/Difference Rule | |
| Product | Product Rule | |
| Quotient | Quotient Rule | |
| Constant Multiple | Constant Multiple Rule |
Differentiate the functions , , and consider the derivative of the product and the quotient , without performing algebraic manipulations until the very end.
We already know that
Now, computing the product, we get:
For the quotient, where we assume , as otherwise would be zero, we get:
The Chain Rule
We have seen the techniques for differentiating basic functions as well as sums, differences, products, quotients, and constant multiples of these functions. However, these techniques do not allow us to differentiate compositions of functions. In this section, we study the rule for finding the derivative of the composition of two or more functions.
Let and be functions such that:
- is differentiable at
- is differentiable at
For the composite function:
the derivative is then defined as:
To differentiate , follow the steps:
- Identify the outer function and the inner function
- Differentiate with respect to its argument to get
- Evaluate by substituting into
- Differentiate with respect to its argument to get
- Compute as
Differentiate .
To do so, we let:
- The outer function be , so
- The inner function be , so
Applying the Chain Rule, we then get:
Differentiate .
To do so, we let:
- The outer function be , so .
- The inner function be , so .
Applying the Chain Rule, we then get:
Finding Extrema
In this section, we focus on an important application of derivatives: finding maxima and minima of functions.
Let be defined on an interval containing , then:
- is the minimum of on if for all
- is the maximum of on if for all
The maximum and minimum values are the extreme values, or extrema, of on .
Let be a continuous function defined on a closed interval . Then has both a maximum and minimum value on .
The Turning Point of a Quadratic Function
Recall from earlier, a turning point (or tipping point) of a graph is a point at which the graph changes direction from increasing to decreasing or vice versa. For a quadratic formula, the formula for the turning point is:
We will later see how to find derive this point by setting the first derivative of the function to zero and solving for (i.e., ).
For , with discriminant , the turning point is:
Since , the parabola opens upwards, and the turning point is a minimum. This can also be confirmed by inspecting the graph.
Derivatives & Local Extrema
The derivative measures the slope of the tangent line at . At a local maximum or minimum, the tangent line is horizontal, meaning:
Such points are also called critical points.
Let be a 2-times differentiable function and a point such that . Then
- If we have a local minimum
- If we have a local maximum
- If or doesn't exist, the test gives no information
Find the local maxima and minima of the function .
We differentiate and obtain
In order to find the points where we solve the quadratic equation . The discriminant is and the roots are thus
Differentiating once again, we obtain
and by calculation, and . We can compute the coordinates ,
Chapter Exercises
Chapter 9: Sequences, Sums & Products
This chapter introduces notation for working with ordered lists of numbers and with repeated addition or multiplication. These ideas appear throughout mathematics whenever we want to describe a pattern compactly instead of writing out every term.
Sequences
A sequence is an ordered list of numbers. For example, the numbers
form a sequence. This is different from a set because, in a sequence, the order of the terms matters. For this reason, when we use variables to represent terms in a sequence, we attach an index to each term:
The numbers in the subscripts are called indices (the plural of index).
A sequence is an ordered list of numbers. We often denote the entire sequence by
where is the term with index .
Summation Notation
Given a sequence and numbers and satisfying , the summation from to of the sequence is written
The variable is called the index of summation. The number is called the lower limit of summation, while the number is called the upper limit of summation.
The index variable is considered a "dummy variable" in the sense that it may be changed to any letter without affecting the value of the summation. For instance,
One place you may encounter summation notation is in mathematical definitions. For example, summation notation allows us to define polynomials as functions of the form:
Here:
- is a non-negative integer (the degree of the polynomial).
- are real constants.
- if .
Find the following sum:
Expanding the notation gives
The sum
can be written using summation notation as
Find the following sum:
The sum
can be written as
Finally, evaluate the following sum:
Expanding the terms gives
Product Notation
If we want to multiply elements of a sequence instead of adding them, we use product notation.
Given a sequence and numbers and satisfying , the product from to of the sequence is written
Again, the variable is the index. The number is the lower limit while the number is the upper limit.
Chapter Exercises
Chapter 10: Mathematical Logic
In this chapter, we introduce the basic concepts of mathematical logic. The principles we explore here are not purely theoretical: they form part of the foundation for digital circuits in computers and for the conditional logic used in programming. Both hardware and software rely on the same algebra of propositions that we will study.
Propositions
A proposition is a declarative statement that can be assigned a definite truth value: true or false, but never both.
The following are examples of propositions:
- "Four is even." (True)
- "1 + 1 is 3." (False)
- "." (True)
- "." (False)
In mathematical logic, propositions mirror the reasoning we use in everyday language, but with strict precision. They can also be compound, formed using logical connectives such as and, or, and not.
This foundation allows us to reason about more complex systems, from proofs in mathematics to conditional statements in computer programs like if and else.
Logical Operations
Simple propositions can be combined to form compound propositions using logical connectives such as and, or, not, if...then..., and if and only if. To avoid ambiguity, we define the meaning of each connective precisely and introduce its standard symbolic representation.
Except for negation (not), which acts on a single proposition, all logical operations act on pairs of propositions. Since each proposition can be either true () or false (), there are four possible combinations of truth values for two propositions. The effect of a logical operation on these combinations is most clearly shown using a truth table.
Logical Conjunction (AND)
If and are propositions, their conjunction, " and ," denoted by , is defined by the truth table:
Each row in the table represents one possible case. The conjunction is true only when both and are true, just as in ordinary language.
The symbols , , and are commonly used as placeholders for propositions, similar to how , , and are used for numeric variables.
Suppose we want to solve for such that and . This means must satisfy both conditions simultaneously:
In Python, we can write this as:
x = 3
if x > 0 and x < 5:
print("x is between 0 and 5")
Logical Disjunction (OR)
If and are propositions, their disjunction, " or ," denoted by , is defined by:
This operation reflects the inclusive or, meaning the result is true if either or both propositions are true.
A quadratic equation has two possible solutions:
In Python, we can write this as:
x = -3
if x == 3 or x == -3:
print("x is a solution to x^2 = 9")
Logical Negation (NOT)
Negation, denoted by , is the only standard operation that applies to a single proposition.
To express that is not equal to , we write
In Python, we can write this as:
x = 7
if not x == 5:
print("x is not 5")
Conditional Statement (IF...THEN...)
The conditional statement "If then ," denoted , is defined by:
The conditional is false only when is true and is false.
The statement "If , then " can be written as
In Python, we can write:
x = 2
if x == 2:
print("Then x squared is", x**2)
Converse and Contrapositive
The converse of is .
For example:
- Original: "If you score 95 or better on the exam, then you will receive an A."
- Converse: "If you receive an A, then you scored 95 or better."
These statements are not logically equivalent.
The contrapositive of is . Unlike the converse, the contrapositive is logically equivalent to the original conditional. This equivalence is often used in proofs because proving the contrapositive can be simpler.
Biconditional (IF AND ONLY IF)
If and are propositions, the biconditional, " if and only if ," denoted , is defined by:
The biconditional is true when and share the same truth value, i.e., both true or both false.
A number is zero if and only if both and :
In Python, we can write:
x = 0
if (x == 0) == (x >= 0 and x <= 0):
print("x is zero")
Logical Implication
A proposition logically implies a proposition (written as or ) if whenever is true, is also true.
Equivalently, the conditional statement is a tautology, meaning it is true in every possible case.
Let be "It is raining" and let be "The ground is wet."
If every time it rains the ground is wet, then we can write:
This does not mean it is currently raining or that the ground is wet; it simply states that the truth of guarantees the truth of .
Note on \rightarrow vs \Rightarrow
The symbols and are related but have different roles:
| Symbol | Usage | Example | Meaning |
|---|---|---|---|
| Conditional inside logic | "If it is raining, then the ground is wet." | Defines a logical relationship between and . | |
| Inference in reasoning | Given "It is raining" and "If it rains, the ground is wet," we can conclude "The ground is wet." | Expresses a reasoning step or consequence. |
Think of as part of the formula itself and as indicating a conclusion or reasoning step in a proof.
Logical Equivalence
Two propositions and are logically equivalent (written as ) if they always have the same truth value.
Equivalently, the biconditional
is a tautology.
Consider:
- : "I have been to Toronto."
- : "I have been to Chicago."
Now compare these two propositions:
- : "I have not been to both Toronto and Chicago."
- : "I have not been to Toronto or I have not been to Chicago."
At first glance, they appear different. But if you examine all possible truth values for and , you will find they always match. Thus:
This relationship is an example of De Morgan's Law.
The condition " is not less than " is equivalent to " is greater than or equal to ":
In Python, we can write this as:
x = 7
if not x < 5:
print("x is greater than or equal to 5")
Tautologies and Contradictions
Understanding tautologies and contradictions is key to working with implication and equivalence.
Tautology
A tautology is a logical expression that is true in every possible case. The symbol is often used to denote a tautology.
Examples of tautologies include:
- ("Either is true, or it is not.")
- ("If both and are true, then is true.")
In any equation, "" is always true.
In Python, we can write this as:
x = 42
if x == x:
print("This is always true")
Contradiction
A contradiction is a logical expression that is false in every possible case. The symbol is often used to denote a contradiction.
Examples of contradictions include:
- (" and not ," which is impossible to be true simultaneously.)
- ("Either or is true, but neither nor is true.")
" and " can never be true:
In Python, we can write this as:
x = 5
if x > 5 and x < 5:
print("This will never run")
Why Tautologies Matter
- Implication: A statement holds if and only if the conditional is a tautology.
- Equivalence: Two statements and are equivalent if the biconditional is a tautology.
This connection between tautologies, implication, and equivalence is fundamental to mathematical logic and proof techniques.
Chapter Exercises
Chapter 11: Probability
We see probabilities almost every day in our lives. When you pick up the newspaper or read the news on the internet, you may encounter statements such as "there is a 60% chance of rain today" or "a poll shows that 52% of voters approve of the president's job performance." Probabilities are essential in sports, games, and gambling establishments, but probabilities are also used to make business decisions, figure out insurance premiums, and determine the price of raffle tickets. In its most general sense, probability provides a way to measure the chance or likelihood that something will happen.
Probability Terminology
Before discussing how to find probabilities, we need to familiarize ourselves with some basic terminology. When studying probability, we consider a random experiment to be an activity or operation that gives a result that can be observed but not predicted ahead of time. If we roll a pair of dice, pick a card from a deck of playing cards, spin a spinner, or randomly select a person and observe their hair color, we are executing an experiment and observing the result.
Any possible result of conducting an experiment is called an outcome. For the experiment of flipping a coin, there are only two outcomes: heads or tails. For the experiment of rolling a single die, there are six outcomes: , , , , , or . For an experiment, this collection of all possible outcomes is called the sample space.
An event is a collection of outcomes from an experiment. In some instances events contain only one outcome, while at other times an event may contain more than one outcome. Consider the experiment of rolling a single die. The event "rolling a 3" contains only the outcome , while the event "rolling an even number" contains the outcomes .
A random experiment is an activity or operation with a result that cannot be predicted ahead of time.
Any result from conducting an experiment is called an outcome.
The sample space of an experiment is the set of all its possible outcomes.
An event is a subset of the sample space and describes a collection of outcomes.
Consider an experiment of rolling a single die. When we roll it, only one outcome will occur, but we are unsure which outcome. There are six possible outcomes, so the sample space is
- "Rolling a 2" is an event that contains only one outcome: .
- "Rolling a number greater than 2" is another event that contains multiple outcomes: .
Two pennies are tossed at the same time. Both pennies may land heads up (which we write as HH), or the first penny might land heads up and the second one tails up (which we write as HT), and so on. Write the sample space for the experiment and list the outcomes in the event "getting at least one heads."
The sample space for this experiment is
If we define event as "getting at least one heads," the outcomes in event can be written as
Gabe performs an experiment of flipping a coin and then rolling a regular six-sided die.
- Give the sample space for how the coin and die could land.
- Give the outcomes in event : rolls an odd number.
- Give the outcomes in event : gets tails and rolls an even number.
Answer:
Probability is one way to measure the chance or likelihood that an event will occur. Probability is usually denoted in function notation by , and the event is denoted by a capital letter such as , , or . The mathematical notation that indicates the probability that event happens is .
Probability is a numerical measure of the chance or likelihood that an event will occur.
A theoretical probability is based on a mathematical model where the number of outcomes in the event is compared with the number of outcomes in the sample space of an experiment. If the outcomes are equally likely, a formula for the theoretical probability of event is
Let's apply this formula in some relatively simple examples.
Consider the experiment of rolling a regular six-sided die. Find the probability of each event:
- rolling a 5
- rolling an even number
- rolling a number greater than 4
- rolling a 7
- rolling a number less than 7
There are possible equally likely outcomes in the sample space:
-
There is only one outcome in the event "rolling a 5": . Thus,
-
There are three outcomes in the event "rolling an even number": . Thus,
-
There are two outcomes in the event "rolling a number greater than 4": . Thus,
-
There are no outcomes in the event "rolling a 7": . Thus,
-
There are six outcomes in the event "rolling a number less than 7": . Thus,
The previous example illustrates some important properties about values that can be legitimate probabilities.
- The number of outcomes in an event can never be lower than . So, the smallest a probability can be is . If the probability of an event is , we say that event is impossible.
- The number of outcomes in an event can never be more than the number of outcomes in the sample space. Therefore, the largest a probability can be is . If the probability of an event is , we say that event is certain.
- The probability of any event must always fall between and , inclusive. In the course of this chapter, if you compute a probability and get an answer that is negative or greater than , you have made a mistake and should recheck your work.
An event that cannot occur has probability . This event is impossible.
An event that must occur has probability . This event is certain.
The probability of any event must be between and , inclusive. That is,
Recall the experiment in which two pennies are tossed simultaneously and how they land is recorded. Find the probability of getting each result:
- exactly two heads
- exactly one head
- at least one head
- more than two heads
The sample space for this experiment is .
- The event "exactly two heads" occurs in one outcome, :
- The event "exactly one head" occurs in two outcomes, :
- The event "at least one head" occurs in three outcomes, :
- The event "more than two heads" occurs in zero outcomes, :
A theoretical probability is based on a mathematical model where all outcomes are equally likely to occur.
An empirical probability is based on collected data and is the relative frequency of the event occurring.
Lawrence is playing with a standard 52-card deck and wants to find the probability of selecting a queen from the deck.
The theoretical probability that Lawrence pulls a single queen is
or about .
If Lawrence decides to try it out times and pulls a queen at random times in trials of "pull a card, record it, put it back," the empirical probability of pulling a queen is
or about .
The Law of Large Numbers
Flipping a coin is often used to randomly make a decision when there are only two choices. For example, you may flip a coin to decide whether you have steak or fish for dinner. Or, a referee uses a coin flip to decide which football team receives the ball prior to kickoff. The reason why a coin flip seems fair in these circumstances is that most of us agree that the probability of getting heads (and tails) on a coin is . But what does this mean in practice?
Does that mean if we flip a coin twice we will get heads exactly once? If a coin is tossed times, will we necessarily get heads five times? Most of us intuitively know the answer is no. Indeed, if we flip a coin times we might find that it lands on heads times. So what does it mean to say that the probability of heads on a fair coin is ?
To investigate this question, consider the table showing results that may happen when a coin is tossed several times. The top row shows the number of times the coin has been tossed. The next row shows the number of heads that have occurred. The bottom row shows the empirical probability, which is the ratio of the number of heads observed to the number of trials.
| Number of Trials | 10 | 20 | 30 | 40 | 50 |
| Number of Heads Observed | 7 | 13 | 17 | 22 | 26 |
| Empirical Probability of Heads |
Notice that as the number of trials increases, the empirical probability gets closer to , which is what we expect to happen theoretically. In fact, if we kept increasing the number of trials, we would find that the empirical probability would eventually be very close to .
This relationship between empirical probability and theoretical probability can be summarized by the Law of Large Numbers. The probability of an event applies to a large number of trials, not a single trial or a few trials. We should not be surprised that the empirical probability calculated from only a few trials is different from the theoretical probability. It is only empirical probability calculated over the long run that gives an accurate probability.
The Law of Large Numbers states that we can only expect the empirical probability of an event to approximate its true probability when the number of trials of the experiment is large.
Chapter 12: Statistics
Statistics gives us tools for collecting, organizing, describing, and interpreting data. In this chapter, we introduce basic statistical vocabulary, methods for displaying data, and numerical summaries for the center and spread of a data set.
Populations and Samples
The population of a study is the group the collected data is intended to describe.
A parameter is a value (average, percentage, etc.) calculated using all the data from a population.
Parameters are usually denoted with Greek letters.
A sample is a smaller subset of the entire population, ideally one that is fairly representative of the whole population.
A statistic is a value (average, percentage, etc.) calculated using the data from a sample.
Categorizing Data
A variable is any characteristic that is measured from an object or individual.
Once we have gathered data, we might wish to classify it. Roughly speaking, data can be classified as categorical data or quantitative data.
A qualitative (categorical) variable represents a characteristic. Qualitative variables are not inherently numbers, so they cannot be added, multiplied, or averaged, but they can be represented graphically with graphs such as bar graphs.
Examples: gender, hair color, race, nationality, religion, course grade, year in college, etc.
A quantitative (numerical) variable represents a measurable quantity. Quantitative variables are inherently numbers, so they can be added, multiplied, averaged, and displayed graphically.
Examples: height, weight, number of cats owned, score of a football game, etc.
Quantitative variables can be further subdivided into continuous and discrete variables.
A continuous variable can take on an uncountable number of values in a range. In other words, the variable can be any number in a range of values. Continuous variables are usually things that are measured.
Examples: height, weight, foot size, time to take a test, length, etc.
A discrete variable can take on only specific values in a range. Discrete variables are usually things that you count.
Examples: IQ, shoe size, family size, number of cats owned, score in a football game, etc.
Sampling Methods
A random sample is one in which each member of the population has an equal probability of being chosen. A simple random sample is one in which every member of the population and any group of members has an equal probability of being chosen.
A sampling method is biased if every member of the population does not have equal likelihood of being in the sample.
A stratified sample is obtained by dividing the population into meaningful groups, called strata, and then taking a random sample from each group.
Presenting Data Graphically
Once we have collected data, we need to start analyzing it. One way to display and summarize data is to use statistical graphing techniques. The type of graph we use depends on the type of data collected. Qualitative data use graphs like bar graphs and pie graphs. Quantitative data use graphs such as histograms and frequency polygons.
In order to create graphs, we must first organize and summarize the individual data values in the form of a frequency distribution. A frequency distribution is a listing of the data values (or groups of data values) and how often those data values occur.
- Frequency is the number of times a data value or group of data values (called a class) occurs in a data set.
- A frequency distribution is a listing of each data value or class of data values along with its frequency.
- Relative frequency is the frequency divided by , the size of the sample. This gives the proportion of the entire data set represented by each value or class. Relative frequencies are expressed as fractions, decimals, or percentages.
- A relative frequency distribution is a listing of each data value or class of data values along with its relative frequency.
The method of creating a frequency distribution depends on whether we are working with qualitative data or quantitative data. We will now look at how to create each type of frequency distribution according to the type of data and the graphs that go with them.
A bar graph displays a bar for each category. The length of each bar indicates the frequency of that category.
To construct a bar graph, we draw a vertical axis and a horizontal axis. The vertical direction has a scale and measures the frequency of each category. The horizontal axis has no numerical scale in this instance but lists the categories.
A histogram is like a bar graph, but the horizontal axis is a number line and the bars represent numerical intervals.
Measures of Central Tendency
In addition to graphical and verbal descriptions of data, we can use numbers to summarize quantitative data distributions. We want to know what a typical, average, or representative value for a set of data is (the center of the data), and how spread out the values are in the data set. In this section we explore measures of central tendency, and in the next section we will explore measures of spread.
Mean
We need to be careful with using the word "average" as it means different things to different people in different contexts. One of the most common uses of the word "average" is what mathematicians and statisticians call the arithmetic mean, or just the mean for short. The mean is what most people think of when they use the word "average," but we should try to use statistical terms to be precise.
The mean of a set of data is found as the sum of the data values divided by the number of values. Symbolically, the formula for the sample mean is:
where each is the th data value and is the sample size. The expression is a short way to write the data values added together.
We use the symbol to represent the mean, while is the symbol for a single measurement. We say "x bar."
A sample of 100 families in a particular neighborhood are asked their annual household income, to the nearest 5 thousand dollars. The results are summarized in the frequency table below. What is the mean annual household income for this neighborhood?
| Income (thousand dollars) | 15 | 20 | 25 | 30 | 35 | 40 | 45 | 50 |
|---|---|---|---|---|---|---|---|---|
| Frequency | 6 | 8 | 11 | 17 | 19 | 20 | 12 | 7 |
Calculating the mean by hand could get tricky if we try to actually add 100 values. We want to add all 100 values and divide by 100:
The mean household income of our sample is thousand dollars, or .
Continuing from the previous example, suppose a new family with a household income of 5 million dollars moves into the neighborhood. This is 5,000 thousand dollars. Including this in the sample, the mean is now:
While thousand dollars (about ) is the correct mean household income, it no longer represents a "typical" value.
Imagine the data values on a see-saw or balance scale. The mean is the value that keeps the data in balance. In the graph of the household income data, the million data value is so far out to the right that the mean has to adjust upward to keep things in balance.
For this reason, when working with data sets that have outliers, values far outside the primary grouping, it is common to use a different measure of center: the median.
A data value that is much higher or lower than all of the other data values is called an outlier. Sometimes outliers are unusual data values that are interesting and should be studied further, and sometimes they are mistakes.
Median
The median is the value found in the middle of an ordered data set.
There is no symbol or formula for the median. To find the median, order the data values from smallest to largest and then count from both ends inward toward the center one data value at a time until reaching the middle.
If there are an odd number of data values, then there is one middle data value and that is the median.
If there are an even number of data values, then there are two middle data values. The median is the mean of those two data values.
Find the median of these quiz scores:
It is helpful to mark or cross off the numbers in the original data set as you list them to make sure you do not miss any. Also, be sure to count the number of data values in the ordered list to make sure it matches the number of data values in the original list.
In this example there are quiz scores. When the distribution contains an odd number of data values, there will be a single value in the middle and that value is the median. For small data sets, we can "walk" one value at a time from the ends of the ordered list toward the center to find the median:
The median test score is 6 points.
Suppose another quiz score needs to be included in the set of quiz scores in the previous example. Someone in the class got a perfect score of 20 points on this very difficult quiz.
The ordered list of data is now:
There are now quiz scores in our sample. When the distribution contains an even number of data values, there will be a pair of values in the middle rather than a single value. We find the mean of those middle two values.
The median test score is points. It is important to notice that despite adding an outlier quiz score to the data set, the median is largely unaffected. The median quiz score for the new distribution is 6.5 points when it was 6 points before.
Mode
The mode is the data value that occurs most frequently in the data set.
A data set may have no mode, one mode (unimodal), or multiple modes (bimodal, multimodal).
Measures of Spread and Position
Consider these three sets of student quiz scores on a 10-point quiz:
- Class A:
- Class B:
- Class C:
All these data sets have mean and median , yet the three sets of scores are clearly quite different.
In Class A, everyone had the same score. In Class B, half the class got no points and the other half got a perfect score of 10 points. Scores in Class C were not as consistent as those in Class A but also not as widely varied as those in Class B.
This scenario shows that, in addition to the mean and median, which measure the "typical" value of a data set, we also need a way to measure how "spread out" or varied each data set is. There are several ways to measure the variation and locate positions in a data distribution. In this section we explore range, standard deviation, percentiles, quartiles, and the interquartile range (IQR). We also examine a graphical representation of spread using a box plot.
Range
The first and simplest way to measure spread is the range. Calculation of the range uses only two values from the data set: the largest value and the smallest value. The range is the distance between these two values.
The range is the difference between the maximum value and the minimum value of the data set.
Refer to the three sets of student quiz scores from the introduction to this section.
- For Class A, the range is 0 since both the maximum and minimum are the same: .
- For Class B, the range is 10 since .
- For Class C, the range is 2 since .
In this example, the range seems to reveal how spread out the data is. However, suppose we add a fourth set of quiz scores:
Quiz scores from this class also have a mean and median of . The range is like Class B, yet this data set is quite different than Class B. To more accurately measure the difference in spreads between these two sets of data, we will have to turn to more sophisticated measures of variation.
Find the range for each data set.
- Set A:
- Set B:
For both sets of data, the range is . However, most of the data in Set B is closer together, except for the extremes. There seems to be less variability in the data in Set B than in the data in Set A. The range focuses only on the two extreme values and ignores all the data between the extremes. So, we need a better way to quantify the spread.
Standard Deviation
We saw that the range focuses on the difference between the maximum and minimum values. What if we focused on the differences between each of the data values and the center? The center we will use is the mean. The difference between a data value and the mean of the distribution is called a deviation.
The difference between a data value and the mean of the data distribution is called the deviation from the mean.
To see how deviations work, consider the following temperature data set, whose sample mean is approximately :
Notice that some of the deviations are positive and some of them are negative. The sum of the deviations is around zero. If there had been no rounding of the mean, then the sum of the deviations would have been exactly .
So what does that tell us? Does this imply that on average the data values are a distance of zero units from the mean? No. It just means that some of the data values are above the mean and some are below the mean. The negative deviations are for data values that are below the mean, and the positive deviations are for data values that are above the mean. The positive and negative deviations from the mean cancel each other out.
We need to eliminate the signs of the deviations so we can measure the distance from the mean. Squaring a number is a widely accepted way to make all of the numbers positive. We continue building the table by adding a third column that contains the squares of the deviations from the mean.
Now that we have the sum of the squared deviations, we should find the mean of these values. However, since this is a sample, the normal way to find the mean (summing and dividing by ) does not estimate the true population spread correctly. It would underestimate the true value. So, to calculate a better estimate, we divide by a slightly smaller number, . This adjusted average is known as the sample variance. The sample variance is the sum of the squared deviations from the mean divided by . The symbol for sample variance is , and the formula for the sample variance is
For this data set, the sample variance is
The variance measures the average squared distance from the mean. Since we want to know the average distance from the mean, we need to take the square root at this point. The result is the sample standard deviation. The sample standard deviation is the square root of the variance and measures the average distance the data values are from the mean. The symbol for sample standard deviation is , and the formula for the sample standard deviation is
Thus, for this data set, the sample standard deviation is
The units are the same as the original data.
The standard deviation is a measure of spread based on how far each data value deviates from the mean.
To compute the sample standard deviation by hand:
- Find the deviation of each data value from the mean. In other words, subtract the mean from the data value.
- Square each deviation.
- Add the squared deviations.
- Divide by one fewer than the number of data values, . This value is the variance.
- Take the square root of the result.
Percentiles
The th percentile is a value of the data set where of the data set is less than or equal to that data value.
For example, if a data value is at the th percentile, then of the data values fall at or below this value (and of the data values fall above this value).
We see percentiles in many places in our lives. If you take any standardized test, your score is usually given as a percentile. If you take your child to the doctor, their height and weight are given as percentiles so they can be compared to other children their age. If your child is tested for gifted or behavior problems, the score is given as a percentile. If your child has a score on a gifted test that is at the 92nd percentile, then that means 92% of all of the children who took the same gifted test scored the same or lower than your child. Of course, that also means that 8% scored higher than your child.
A percentile is a measure that helps you determine where a data value is located relative to the other data values. For example, a test grade reported as a percentile does not tell you whether you did well or poorly. It does not tell you whether you passed or failed. It only tells you how well you did relative to the rest of the students who took the same test. For this reason, we often refer to a percentile as a measure of position.
Five-Number Summary
Three very common percentiles are the first, second, and third quartiles. Quartiles are locations in the data set that split the data distribution into quarters, or sections that each contain of the data values.
Quartiles are values that divide the data in quarters:
- The first quartile () is the value so that of the data values are at or below this value. This is also known as the 25th percentile.
- The second quartile () is the value so that of the data values are at or below this value. This is also known as the 50th percentile, but more commonly called the median.
- The third quartile () is the value so that of the data values are at or below this value. This is also known as the 75th percentile.
To find the quartiles:
- Order the data from smallest to largest.
- Find the median. This is the second quartile, .
- Find the median of the lower half of the data values (all values to the left of the median's location). This is the first quartile, .
- Find the median of the upper half of the data values (all values to the right of the median's location). This is the third quartile, .
Like the standard deviation, the quartiles are used to measure how spread out the data are, but unlike the standard deviation the quartiles are not a single-number summary of spread. The three quartiles, together with the maximum and minimum values, create a measure of spread called the five-number summary.
The five-number summary takes the form: Minimum, , Median, , Maximum.
These five values divide the data into quarters: of the data is between the minimum and , is between and the median, is between the median and , and is between and the maximum value.
Moreover, of the data lies between and . The distance between and is called the interquartile range.
The interquartile range (IQR) measures the spread in the middle of the data. Subtract from to find its value:
The scores for a women's golf team in tournament play are listed below. Find the five-number summary and the IQR.
Data: .
First, order the data values from smallest to largest. The median will be the mean of the two middle values since there are an even number of data values.
- The median is .
- There are 6 numbers below the median: . The median of these six numbers is .
- There are 6 numbers above the median: . The median of these six numbers is .
- The minimum is 79 and the maximum is 111.
Thus, the five-number summary is , , , , . The .
Box-and-Whiskers Plots
A box plot is created by first setting a scale (number line) as a guideline for the box plot. Then, draw a rectangle that spans from to above the number line. Mark the median with a vertical line through the rectangle. Next, draw symbols (dots, small vertical lines, etc.) for the minimum and maximum points to the sides of the rectangle. Finally, draw horizontal lines from the sides of the rectangle out to the symbols. These horizontal lines are known as "whiskers."
Using the results of the golf scores tournament from the previous example, a box plot would show the minimum at , at , the median at , at , and the maximum at .